面对大量用户访问、高并发请求,海量数据,可以使用高性能的服务器、大型数据库,存储设备,高性能Web服务器,采用高效率的编程语言比如(Go,Scala)等,当单机容量达到极限时,我们需要考虑业务拆分和分布式部署,来解决大型网站访问量大,并发量高,海量数据的问题。
从单机网站到分布式网站,很重要的区别是业务拆分和分布式部署,将应用拆分后,部署到不同的机器上,实现大规模分布式系统。分布式和业务拆分解决了,从集中到分布的问题,但是每个部署的独立业务还存在单点的问题和访问统一入口问题,为解决单点故障,我们可以采取冗余的方式。将相同的应用部署到多台机器上。解决访问统一入口问题,我们可以在集群前面增加负载均衡设备,实现流量分发。
负载均衡(Load Balance),意思是将负载(工作任务,访问请求)进行平衡、分摊到多个操作单元(服务器,组件)上进行执行。是解决高性能,单点故障(高可用),扩展性(水平伸缩)的终极解决方案。
本文是负载均衡详解的第一篇文章,介绍负载均衡的原理,负载均衡分类(DNS负载均衡,HTTP负载均衡,IP负载均衡,链路层负载均衡,混合型P负载均衡)。
本次分享大纲
负载均衡原理
DNS负载均衡
HTTP负载均衡
IP负载均衡
链路层负载均衡
混合型P负载均衡
一、负载均衡原理
系统的扩展可分为纵向(垂直)扩展和横向(水平)扩展。纵向扩展,是从单机的角度通过增加硬件处理能力,比如CPU处理能力,内存容量,磁盘等方面,实现服务器处理能力的提升,不能满足大型分布式系统(网站),大流量,高并发,海量数据的问题。因此需要采用横向扩展的方式,通过添加机器来满足大型网站服务的处理能力。
比如:一台机器不能满足,则增加两台或者多台机器,共同承担访问压力。这就是典型的集群和负载均衡架构:如下图:
![]() 应用集群:将同一应用部署到多台机器上,组成处理集群,接收负载均衡设备分发的请求,进行处理,并返回相应数据。
负载均衡设备:将用户访问的请求,根据负载均衡算法,分发到集群中的一台处理服务器。(一种把网络请求分散到一个服务器集群中的可用服务器上去的设备)负载均衡的作用(解决的问题):
1.解决并发压力,提高应用处理性能(增加吞吐量,加强网络处理能力);
2.提供故障转移,实现高可用;
3.通过添加或减少服务器数量,提供网站伸缩性(扩展性);
4.安全防护;(负载均衡设备上做一些过滤,黑白名单等处理)
二、负载均衡分类
根据实现技术不同,可分为DNS负载均衡,HTTP负载均衡,IP负载均衡,链路层负载均衡等。
2.1DNS负载均衡
最早的负载均衡技术,利用域名解析实现负载均衡,在DNS服务器,配置多个A记录,这些A记录对应的服务器构成集群。大型网站总是部分使用DNS解析,作为第一级负载均衡。如下图:
应用集群:将同一应用部署到多台机器上,组成处理集群,接收负载均衡设备分发的请求,进行处理,并返回相应数据。
负载均衡设备:将用户访问的请求,根据负载均衡算法,分发到集群中的一台处理服务器。(一种把网络请求分散到一个服务器集群中的可用服务器上去的设备)负载均衡的作用(解决的问题):
1.解决并发压力,提高应用处理性能(增加吞吐量,加强网络处理能力);
2.提供故障转移,实现高可用;
3.通过添加或减少服务器数量,提供网站伸缩性(扩展性);
4.安全防护;(负载均衡设备上做一些过滤,黑白名单等处理)
二、负载均衡分类
根据实现技术不同,可分为DNS负载均衡,HTTP负载均衡,IP负载均衡,链路层负载均衡等。
2.1DNS负载均衡
最早的负载均衡技术,利用域名解析实现负载均衡,在DNS服务器,配置多个A记录,这些A记录对应的服务器构成集群。大型网站总是部分使用DNS解析,作为第一级负载均衡。如下图:
![]() 优点
使用简单:负载均衡工作,交给DNS服务器处理,省掉了负载均衡服务器维护的麻烦
提高性能:可以支持基于地址的域名解析,解析成距离用户最近的服务器地址,可以加快访问速度,改善性能;
缺点
可用性差:DNS解析是多级解析,新增/修改DNS后,解析时间较长;解析过程中,用户访问网站将失败;
扩展性低:DNS负载均衡的控制权在域名商那里,无法对其做更多的改善和扩展;
维护性差:也不能反映服务器的当前运行状态;支持的算法少;不能区分服务器的差异(不能根据系统与服务的状态来判断负载)
实践建议
将DNS作为第一级负载均衡,A记录对应着内部负载均衡的IP地址,通过内部负载均衡将请求分发到真实的Web服务器上。一般用于互联网公司,复杂的业务系统不合适使用。如下图:
优点
使用简单:负载均衡工作,交给DNS服务器处理,省掉了负载均衡服务器维护的麻烦
提高性能:可以支持基于地址的域名解析,解析成距离用户最近的服务器地址,可以加快访问速度,改善性能;
缺点
可用性差:DNS解析是多级解析,新增/修改DNS后,解析时间较长;解析过程中,用户访问网站将失败;
扩展性低:DNS负载均衡的控制权在域名商那里,无法对其做更多的改善和扩展;
维护性差:也不能反映服务器的当前运行状态;支持的算法少;不能区分服务器的差异(不能根据系统与服务的状态来判断负载)
实践建议
将DNS作为第一级负载均衡,A记录对应着内部负载均衡的IP地址,通过内部负载均衡将请求分发到真实的Web服务器上。一般用于互联网公司,复杂的业务系统不合适使用。如下图:
![]() 1.3 IP负载均衡
在网络层通过修改请求目标地址进行负载均衡。
用户请求数据包,到达负载均衡服务器后,负载均衡服务器在操作系统内核进程获取网络数据包,根据负载均衡算法得到一台真实服务器地址,然后将请求目的地址修改为,获得的真实ip地址,不需要经过用户进程处理。
真实服务器处理完成后,响应数据包回到负载均衡服务器,负载均衡服务器,再将数据包源地址修改为自身的ip地址,发送给用户浏览器。如下图:
1.3 IP负载均衡
在网络层通过修改请求目标地址进行负载均衡。
用户请求数据包,到达负载均衡服务器后,负载均衡服务器在操作系统内核进程获取网络数据包,根据负载均衡算法得到一台真实服务器地址,然后将请求目的地址修改为,获得的真实ip地址,不需要经过用户进程处理。
真实服务器处理完成后,响应数据包回到负载均衡服务器,负载均衡服务器,再将数据包源地址修改为自身的ip地址,发送给用户浏览器。如下图:
![]() IP负载均衡,真实物理服务器返回给负载均衡服务器,存在两种方式:
(1)负载均衡服务器在修改目的ip地址的同时修改源地址。将数据包源地址设为自身盘,即源地址转换(snat)。
(2)将负载均衡服务器同时作为真实物理服务器集群的网关服务器。
优点:
(1)在内核进程完成数据分发,比在应用层分发性能更好;
缺点:
(2)所有请求响应都需要经过负载均衡服务器,集群最大吞吐量受限于负载均衡服务器网卡带宽;
2.4链路层负载均衡
在通信协议的数据链路层修改mac地址,进行负载均衡。
数据分发时,不修改ip地址,指修改目标mac地址,配置真实物理服务器集群所有机器虚拟ip和负载均衡服务器ip地址一致,达到不修改数据包的源地址和目标地址,进行数据分发的目的。
实际处理服务器ip和数据请求目的ip一致,不需要经过负载均衡服务器进行地址转换,可将响应数据包直接返回给用户浏览器,避免负载均衡服务器网卡带宽成为瓶颈。也称为直接路由模式(DR模式)。如下图:
IP负载均衡,真实物理服务器返回给负载均衡服务器,存在两种方式:
(1)负载均衡服务器在修改目的ip地址的同时修改源地址。将数据包源地址设为自身盘,即源地址转换(snat)。
(2)将负载均衡服务器同时作为真实物理服务器集群的网关服务器。
优点:
(1)在内核进程完成数据分发,比在应用层分发性能更好;
缺点:
(2)所有请求响应都需要经过负载均衡服务器,集群最大吞吐量受限于负载均衡服务器网卡带宽;
2.4链路层负载均衡
在通信协议的数据链路层修改mac地址,进行负载均衡。
数据分发时,不修改ip地址,指修改目标mac地址,配置真实物理服务器集群所有机器虚拟ip和负载均衡服务器ip地址一致,达到不修改数据包的源地址和目标地址,进行数据分发的目的。
实际处理服务器ip和数据请求目的ip一致,不需要经过负载均衡服务器进行地址转换,可将响应数据包直接返回给用户浏览器,避免负载均衡服务器网卡带宽成为瓶颈。也称为直接路由模式(DR模式)。如下图:
![]() 优点:性能好;
缺点:配置复杂;
实践建议:DR模式是目前使用最广泛的一种负载均衡方式。
2.5混合型负载均衡
由于多个服务器群内硬件设备、各自的规模、提供的服务等的差异,可以考虑给每个服务器群采用最合适的负载均衡方式,然后又在这多个服务器群间再一次负载均衡或群集起来以一个整体向外界提供服务(即把这多个服务器群当做一个新的服务器群),从而达到最佳的性能。将这种方式称之为混合型负载均衡。
此种方式有时也用于单台均衡设备的性能不能满足大量连接请求的情况下。是目前大型互联网公司,普遍使用的方式。
方式一,如下图:
优点:性能好;
缺点:配置复杂;
实践建议:DR模式是目前使用最广泛的一种负载均衡方式。
2.5混合型负载均衡
由于多个服务器群内硬件设备、各自的规模、提供的服务等的差异,可以考虑给每个服务器群采用最合适的负载均衡方式,然后又在这多个服务器群间再一次负载均衡或群集起来以一个整体向外界提供服务(即把这多个服务器群当做一个新的服务器群),从而达到最佳的性能。将这种方式称之为混合型负载均衡。
此种方式有时也用于单台均衡设备的性能不能满足大量连接请求的情况下。是目前大型互联网公司,普遍使用的方式。
方式一,如下图:
![]() 以上模式适合有动静分离的场景,反向代理服务器(集群)可以起到缓存和动态请求分发的作用,当时静态资源缓存在代理服务器时,则直接返回到浏览器。如果动态页面则请求后面的应用负载均衡(应用集群)。
方式二,如下图:
以上模式适合有动静分离的场景,反向代理服务器(集群)可以起到缓存和动态请求分发的作用,当时静态资源缓存在代理服务器时,则直接返回到浏览器。如果动态页面则请求后面的应用负载均衡(应用集群)。
方式二,如下图:
![]() 以上模式,适合动态请求场景。
因混合模式,可以根据具体场景,灵活搭配各种方式,以上两种方式仅供参考。
三、负载均衡算法
常用的负载均衡算法有,轮询,随机,最少链接,源地址散列,加权等方式;
3.1 轮询
将所有请求,依次分发到每台服务器上,适合服务器硬件同相同的场景。
优点:服务器请求数目相同;
缺点:服务器压力不一样,不适合服务器配置不同的情况;
3.2 随机
请求随机分配到各个服务器。
优点:使用简单;
缺点:不适合机器配置不同的场景;
3.3 最少链接
将请求分配到连接数最少的服务器(目前处理请求最少的服务器)。
优点:根据服务器当前的请求处理情况,动态分配;
缺点:算法实现相对复杂,需要监控服务器请求连接数;
3.4 Hash(源地址散列)
根据IP地址进行Hash计算,得到IP地址。
优点:将来自同一IP地址的请求,同一会话期内,转发到相同的服务器;实现会话粘滞。
缺点:目标服务器宕机后,会话会丢失;
3.5 加权
在轮询,随机,最少链接,Hash’等算法的基础上,通过加权的方式,进行负载服务器分配。
优点:根据权重,调节转发服务器的请求数目;
缺点:使用相对复杂;
四、硬件负载均衡
采用硬件的方式实现负载均衡,一般是单独的负载均衡服务器,价格昂贵,一般土豪级公司可以考虑,业界领先的有两款,F5和A10。
使用硬件负载均衡,主要考虑一下几个方面:
(1)功能考虑:功能全面支持各层级的负载均衡,支持全面的负载均衡算法,支持全局负载均衡;
(2)性能考虑:一般软件负载均衡支持到5万级并发已经很困难了,硬件负载均衡可以支持
(3)稳定性:商用硬件负载均衡,经过了良好的严格的测试,从经过大规模使用,在稳定性方面高;
(4)安全防护:硬件均衡设备除具备负载均衡功能外,还具备防火墙,防DDOS攻击等安全功能;
(5)维护角度:提供良好的维护管理界面,售后服务和技术支持;
(6)土豪公司:F5 Big Ip 价格:15w~55w不等;A10 价格:55w-100w不等;
缺点
(1)价格昂贵;
(2)扩展能力差;
4.4小结
(1)一般硬件的负载均衡也要做双机高可用,因此成本会比较高。
(2)互联网公司一般使用开源软件,因此大部分应用采用软件负载均衡;部分采用硬件负载均衡。
比如某互联网公司,目前是使用几台F5做全局负载均衡,内部使用Nginx等软件负载均衡。
一、软件负载均衡概述
硬件负载均衡性能优越,功能全面,但是价格昂贵,一般适合初期或者土豪级公司长期使用。因此软件负载均衡在互联网领域大量使用。常用的软件负载均衡软件有Nginx,Lvs,HaProxy等。
二、Ngnix负载均衡
Ngnix是一款轻量级的Web服务器/反向代理服务器,工作在七层Http协议的负载均衡系统。具有高性能、高并发、低内存使用等特点。是一个轻量级的Http和反向代理服务器。Nginx使用epoll and kqueue作为开发模型。能够支持高达 50,000 个并发连接数的响应。
操作系统:Liunx,Windows(Linux、FreeBSD、Solaris、Mac OS X、AIX以及Microsoft Windows)
开发语言:C
并发性能:官方支持每秒5万并发,实际国内一般到每秒2万并发,有优化到每秒10万并发的。具体性能看应用场景。
2.1.特点
1.模块化设计:良好的扩展性,可以通过模块方式进行功能扩展。
2.高可靠性:主控进程和worker是同步实现的,一个worker出现问题,会立刻启动另一个worker。
3.内存消耗低:一万个长连接(keep-alive),仅消耗2.5MB内存。
4.支持热部署:不用停止服务器,实现更新配置文件,更换日志文件、更新服务器程序版本。
5.并发能力强:官方数据每秒支持5万并发;
6.功能丰富:优秀的反向代理功能和灵活的负载均衡策略
2.2.功能
2.2.1基本功能
支持静态资源的web服务器。
http,smtp,pop3协议的反向代理服务器、缓存、负载均衡;
支持FASTCGI(fpm)
支持模块化,过滤器(让文本可以实现压缩,节约带宽),ssl及图像大小调整。
内置的健康检查功能
基于名称和ip的虚拟主机
定制访问日志
支持平滑升级
支持KEEPALIVE
支持url rewrite
支持路径别名
支持基于IP和用户名的访问控制。
支持传输速率限制,支持并发数限制。
2.2.2扩展功能
2.2.3性能
Nginx的高并发,官方测试支持5万并发连接。实际生产环境能到2-3万并发连接数。10000个非活跃的HTTP keep-alive 连接仅占用约2.5MB内存。三万并发连接下,10个Nginx进程,消耗内存150M。淘宝tengine团队测试结果是“24G内存机器上,处理并发请求可达200万”。
2.3架构
2.3.1Nginx的基本工作模式
以上模式,适合动态请求场景。
因混合模式,可以根据具体场景,灵活搭配各种方式,以上两种方式仅供参考。
三、负载均衡算法
常用的负载均衡算法有,轮询,随机,最少链接,源地址散列,加权等方式;
3.1 轮询
将所有请求,依次分发到每台服务器上,适合服务器硬件同相同的场景。
优点:服务器请求数目相同;
缺点:服务器压力不一样,不适合服务器配置不同的情况;
3.2 随机
请求随机分配到各个服务器。
优点:使用简单;
缺点:不适合机器配置不同的场景;
3.3 最少链接
将请求分配到连接数最少的服务器(目前处理请求最少的服务器)。
优点:根据服务器当前的请求处理情况,动态分配;
缺点:算法实现相对复杂,需要监控服务器请求连接数;
3.4 Hash(源地址散列)
根据IP地址进行Hash计算,得到IP地址。
优点:将来自同一IP地址的请求,同一会话期内,转发到相同的服务器;实现会话粘滞。
缺点:目标服务器宕机后,会话会丢失;
3.5 加权
在轮询,随机,最少链接,Hash’等算法的基础上,通过加权的方式,进行负载服务器分配。
优点:根据权重,调节转发服务器的请求数目;
缺点:使用相对复杂;
四、硬件负载均衡
采用硬件的方式实现负载均衡,一般是单独的负载均衡服务器,价格昂贵,一般土豪级公司可以考虑,业界领先的有两款,F5和A10。
使用硬件负载均衡,主要考虑一下几个方面:
(1)功能考虑:功能全面支持各层级的负载均衡,支持全面的负载均衡算法,支持全局负载均衡;
(2)性能考虑:一般软件负载均衡支持到5万级并发已经很困难了,硬件负载均衡可以支持
(3)稳定性:商用硬件负载均衡,经过了良好的严格的测试,从经过大规模使用,在稳定性方面高;
(4)安全防护:硬件均衡设备除具备负载均衡功能外,还具备防火墙,防DDOS攻击等安全功能;
(5)维护角度:提供良好的维护管理界面,售后服务和技术支持;
(6)土豪公司:F5 Big Ip 价格:15w~55w不等;A10 价格:55w-100w不等;
缺点
(1)价格昂贵;
(2)扩展能力差;
4.4小结
(1)一般硬件的负载均衡也要做双机高可用,因此成本会比较高。
(2)互联网公司一般使用开源软件,因此大部分应用采用软件负载均衡;部分采用硬件负载均衡。
比如某互联网公司,目前是使用几台F5做全局负载均衡,内部使用Nginx等软件负载均衡。
一、软件负载均衡概述
硬件负载均衡性能优越,功能全面,但是价格昂贵,一般适合初期或者土豪级公司长期使用。因此软件负载均衡在互联网领域大量使用。常用的软件负载均衡软件有Nginx,Lvs,HaProxy等。
二、Ngnix负载均衡
Ngnix是一款轻量级的Web服务器/反向代理服务器,工作在七层Http协议的负载均衡系统。具有高性能、高并发、低内存使用等特点。是一个轻量级的Http和反向代理服务器。Nginx使用epoll and kqueue作为开发模型。能够支持高达 50,000 个并发连接数的响应。
操作系统:Liunx,Windows(Linux、FreeBSD、Solaris、Mac OS X、AIX以及Microsoft Windows)
开发语言:C
并发性能:官方支持每秒5万并发,实际国内一般到每秒2万并发,有优化到每秒10万并发的。具体性能看应用场景。
2.1.特点
1.模块化设计:良好的扩展性,可以通过模块方式进行功能扩展。
2.高可靠性:主控进程和worker是同步实现的,一个worker出现问题,会立刻启动另一个worker。
3.内存消耗低:一万个长连接(keep-alive),仅消耗2.5MB内存。
4.支持热部署:不用停止服务器,实现更新配置文件,更换日志文件、更新服务器程序版本。
5.并发能力强:官方数据每秒支持5万并发;
6.功能丰富:优秀的反向代理功能和灵活的负载均衡策略
2.2.功能
2.2.1基本功能
支持静态资源的web服务器。
http,smtp,pop3协议的反向代理服务器、缓存、负载均衡;
支持FASTCGI(fpm)
支持模块化,过滤器(让文本可以实现压缩,节约带宽),ssl及图像大小调整。
内置的健康检查功能
基于名称和ip的虚拟主机
定制访问日志
支持平滑升级
支持KEEPALIVE
支持url rewrite
支持路径别名
支持基于IP和用户名的访问控制。
支持传输速率限制,支持并发数限制。
2.2.2扩展功能
2.2.3性能
Nginx的高并发,官方测试支持5万并发连接。实际生产环境能到2-3万并发连接数。10000个非活跃的HTTP keep-alive 连接仅占用约2.5MB内存。三万并发连接下,10个Nginx进程,消耗内存150M。淘宝tengine团队测试结果是“24G内存机器上,处理并发请求可达200万”。
2.3架构
2.3.1Nginx的基本工作模式
![]() 一个master进程,生成一个或者多个worker进程。但是这里master是使用root身份启动的,因为nginx要工作在80端口。而只有管理员才有权限启动小于低于1023的端口。master主要是负责的作用只是启动worker,加载配置文件,负责系统的平滑升级。其它的工作是交给worker。那么当worker被启动之后,也只是负责一些web最简单的工作,而其他的工作都是有worker中调用的模块来实现的。
模块之间是以流水线的方式实现功能的。流水线,指的是一个用户请求,由多个模块组合各自的功能依次实现完成的。比如:第一个模块只负责分析请求首部,第二个模块只负责查找数据,第三个模块只负责压缩数据,依次完成各自工作。来实现整个工作的完成。
他们是如何实现热部署的呢?其实是这样的,我们前面说master不负责具体的工作,而是调用worker工作,他只是负责读取配置文件,因此当一个模块修改或者配置文件发生变化,是由master进行读取,因此此时不会影响到worker工作。在master进行读取配置文件之后,不会立即的把修改的配置文件告知worker。而是让被修改的worker继续使用老的配置文件工作,当worker工作完毕之后,直接当掉这个子进程,更换新的子进程,使用新的规则。
2.3.2Nginx支持的sendfile机制
Sendfile机制,用户将请求发给内核,内核根据用户的请求调用相应用户进程,进程在处理时需要资源。此时再把请求发给内核(进程没有直接IO的能力),由内核加载数据。内核查找到数据之后,会把数据复制给用户进程,由用户进程对数据进行封装,之后交给内核,内核在进行tcp/ip首部的封装,最后再发给客户端。这个功能用户进程只是发生了一个封装报文的过程,却要绕一大圈。因此nginx引入了sendfile机制,使得内核在接受到数据之后,不再依靠用户进程给予封装,而是自己查找自己封装,减少了一个很长一段时间的浪费,这是一个提升性能的核心点。
一个master进程,生成一个或者多个worker进程。但是这里master是使用root身份启动的,因为nginx要工作在80端口。而只有管理员才有权限启动小于低于1023的端口。master主要是负责的作用只是启动worker,加载配置文件,负责系统的平滑升级。其它的工作是交给worker。那么当worker被启动之后,也只是负责一些web最简单的工作,而其他的工作都是有worker中调用的模块来实现的。
模块之间是以流水线的方式实现功能的。流水线,指的是一个用户请求,由多个模块组合各自的功能依次实现完成的。比如:第一个模块只负责分析请求首部,第二个模块只负责查找数据,第三个模块只负责压缩数据,依次完成各自工作。来实现整个工作的完成。
他们是如何实现热部署的呢?其实是这样的,我们前面说master不负责具体的工作,而是调用worker工作,他只是负责读取配置文件,因此当一个模块修改或者配置文件发生变化,是由master进行读取,因此此时不会影响到worker工作。在master进行读取配置文件之后,不会立即的把修改的配置文件告知worker。而是让被修改的worker继续使用老的配置文件工作,当worker工作完毕之后,直接当掉这个子进程,更换新的子进程,使用新的规则。
2.3.2Nginx支持的sendfile机制
Sendfile机制,用户将请求发给内核,内核根据用户的请求调用相应用户进程,进程在处理时需要资源。此时再把请求发给内核(进程没有直接IO的能力),由内核加载数据。内核查找到数据之后,会把数据复制给用户进程,由用户进程对数据进行封装,之后交给内核,内核在进行tcp/ip首部的封装,最后再发给客户端。这个功能用户进程只是发生了一个封装报文的过程,却要绕一大圈。因此nginx引入了sendfile机制,使得内核在接受到数据之后,不再依靠用户进程给予封装,而是自己查找自己封装,减少了一个很长一段时间的浪费,这是一个提升性能的核心点。
![]() 以上内容摘自网友发布的文章,简单一句话是资源的处理,直接通过内核层进行数据传递,避免了数据传递到应用层,应用层再传递到内核层的开销。
目前高并发的处理,一般都采用sendfile模式。通过直接操作内核层数据,减少应用与内核层数据传递。
2.3.3Nginx通信模型(I/O复用机制)
开发模型:epoll和kqueue。
支持的事件机制:kqueue、epoll、rt signals、/dev/poll 、event ports、select以及poll。
支持的kqueue特性包括EV_CLEAR、EV_DISABLE、NOTE_LOWAT、EV_EOF,可用数据的数量,错误代码.
支持sendfile、sendfile64和sendfilev;文件AIO;DIRECTIO;支持Accept-filters和TCP_DEFER_ACCEP.
以上概念较多,大家自行百度或谷歌,知识领域是网络通信(BIO,NIO,AIO)和多线程方面的知识。
2.4均衡策略
nginx的负载均衡策略可以划分为两大类:内置策略和扩展策略。内置策略包含加权轮询和ip hash,在默认情况下这两种策略会编译进nginx内核,只需在nginx配置中指明参数即可。扩展策略有很多,如fair、通用hash、consistent hash等,默认不编译进nginx内核。由于在nginx版本升级中负载均衡的代码没有本质性的变化,因此下面将以nginx1.0.15稳定版为例,从源码角度分析各个策略。
2.4.1. 加权轮询(weighted round robin)
轮询的原理很简单,首先我们介绍一下轮询的基本流程。如下是处理一次请求的流程图:
以上内容摘自网友发布的文章,简单一句话是资源的处理,直接通过内核层进行数据传递,避免了数据传递到应用层,应用层再传递到内核层的开销。
目前高并发的处理,一般都采用sendfile模式。通过直接操作内核层数据,减少应用与内核层数据传递。
2.3.3Nginx通信模型(I/O复用机制)
开发模型:epoll和kqueue。
支持的事件机制:kqueue、epoll、rt signals、/dev/poll 、event ports、select以及poll。
支持的kqueue特性包括EV_CLEAR、EV_DISABLE、NOTE_LOWAT、EV_EOF,可用数据的数量,错误代码.
支持sendfile、sendfile64和sendfilev;文件AIO;DIRECTIO;支持Accept-filters和TCP_DEFER_ACCEP.
以上概念较多,大家自行百度或谷歌,知识领域是网络通信(BIO,NIO,AIO)和多线程方面的知识。
2.4均衡策略
nginx的负载均衡策略可以划分为两大类:内置策略和扩展策略。内置策略包含加权轮询和ip hash,在默认情况下这两种策略会编译进nginx内核,只需在nginx配置中指明参数即可。扩展策略有很多,如fair、通用hash、consistent hash等,默认不编译进nginx内核。由于在nginx版本升级中负载均衡的代码没有本质性的变化,因此下面将以nginx1.0.15稳定版为例,从源码角度分析各个策略。
2.4.1. 加权轮询(weighted round robin)
轮询的原理很简单,首先我们介绍一下轮询的基本流程。如下是处理一次请求的流程图:
![]() 图中有两点需要注意:
第一,如果可以把加权轮询算法分为先深搜索和先广搜索,那么nginx采用的是先深搜索算法,即将首先将请求都分给高权重的机器,直到该机器的权值降到了比其他机器低,才开始将请求分给下一个高权重的机器;
第二,当所有后端机器都down掉时,nginx会立即将所有机器的标志位清成初始状态,以避免造成所有的机器都处在timeout的状态,从而导致整个前端被夯住。
2.4.2. ip hash
ip hash是nginx内置的另一个负载均衡的策略,流程和轮询很类似,只是其中的算法和具体的策略有些变化,如下图所示:
图中有两点需要注意:
第一,如果可以把加权轮询算法分为先深搜索和先广搜索,那么nginx采用的是先深搜索算法,即将首先将请求都分给高权重的机器,直到该机器的权值降到了比其他机器低,才开始将请求分给下一个高权重的机器;
第二,当所有后端机器都down掉时,nginx会立即将所有机器的标志位清成初始状态,以避免造成所有的机器都处在timeout的状态,从而导致整个前端被夯住。
2.4.2. ip hash
ip hash是nginx内置的另一个负载均衡的策略,流程和轮询很类似,只是其中的算法和具体的策略有些变化,如下图所示:
![]() 2.4.3. fair
fair策略是扩展策略,默认不被编译进nginx内核。其原理是根据后端服务器的响应时间判断负载情况,从中选出负载最轻的机器进行分流。这种策略具有很强的自适应性,但是实际的网络环境往往不是那么简单,因此要慎用。
2.4.4 通用hash、一致性hash
这两种也是扩展策略,在具体的实现上有些差别,通用hash比较简单,可以以nginx内置的变量为key进行hash,一致性hash采用了nginx内置的一致性hash环,可以支持memcache。
2.5场景
Ngnix一般作为入口负载均衡或内部负载均衡,结合反向代理服务器使用。以下架构示例,仅供参考,具体使用根据场景而定。
2.5.1入口负载均衡架构
2.4.3. fair
fair策略是扩展策略,默认不被编译进nginx内核。其原理是根据后端服务器的响应时间判断负载情况,从中选出负载最轻的机器进行分流。这种策略具有很强的自适应性,但是实际的网络环境往往不是那么简单,因此要慎用。
2.4.4 通用hash、一致性hash
这两种也是扩展策略,在具体的实现上有些差别,通用hash比较简单,可以以nginx内置的变量为key进行hash,一致性hash采用了nginx内置的一致性hash环,可以支持memcache。
2.5场景
Ngnix一般作为入口负载均衡或内部负载均衡,结合反向代理服务器使用。以下架构示例,仅供参考,具体使用根据场景而定。
2.5.1入口负载均衡架构
![]() Ngnix服务器在用户访问的最前端。根据用户请求再转发到具体的应用服务器或二级负载均衡服务器(LVS)
2.5.2内部负载均衡架构
Ngnix服务器在用户访问的最前端。根据用户请求再转发到具体的应用服务器或二级负载均衡服务器(LVS)
2.5.2内部负载均衡架构
![]() LVS作为入口负载均衡,将请求转发到二级Ngnix服务器,Ngnix再根据请求转发到具体的应用服务器。
2.5.3Ngnix高可用
LVS作为入口负载均衡,将请求转发到二级Ngnix服务器,Ngnix再根据请求转发到具体的应用服务器。
2.5.3Ngnix高可用
![]() 分布式系统中,应用只部署一台服务器会存在单点故障,负载均衡同样有类似的问题。一般可采用主备或负载均衡设备集群的方式节约单点故障或高并发请求分流。
Ngnix高可用,至少包含两个Ngnix服务器,一台主服务器,一台备服务器,之间使用Keepalived做健康监控和故障检测。开放VIP端口,通过防火墙进行外部映射。
DNS解析公网的IP实际为VIP。
三、LVS负载均衡
LVS是一个开源的软件,由毕业于国防科技大学的章文嵩博士于1998年5月创立,用来实现Linux平台下的简单负载均衡。LVS是Linux Virtual Server的缩写,意思是Linux虚拟服务器。
基于IP层的负载均衡调度技术,它在操作系统核心层上,将来自IP层的TCP/UDP请求均衡地转移到不同的 服务器,从而将一组服务器构成一个高性能、高可用的虚拟服务器。
操作系统:Liunx
开发语言:C
并发性能:默认4096,可以修改但需要重新编译。
3.1.功能
LVS的主要功能是实现IP层(网络层)负载均衡,有NAT,TUN,DR三种请求转发模式。
3.1.1LVS/NAT方式的负载均衡集群
NAT是指Network Address Translation,它的转发流程是:Director机器收到外界请求,改写数据包的目标地址,按相应的调度算法将其发送到相应Real Server上,Real Server处理完该请求后,将结果数据包返回到其默认网关,即Director机器上,Director机器再改写数据包的源地址,最后将其返回给外界。这样就完成一次负载调度。
构架一个最简单的LVS/NAT方式的负载均衡集群Real Server可以是任何的操作系统,而且无需做任何特殊的设定,惟一要做的就是将其默认网关指向Director机器。Real Server可以使用局域网的内部IP(192.168.0.0/24)。Director要有两块网卡,一块网卡绑定一个外部IP地址 (10.0.0.1),另一块网卡绑定局域网的内部IP(192.168.0.254),作为Real Server的默认网关。
LVS/NAT方式实现起来最为简单,而且Real Server使用的是内部IP,可以节省Real IP的开销。但因为执行NAT需要重写流经Director的数据包,在速度上有一定延迟;
当用户的请求非常短,而服务器的回应非常大的情况下,会对Director形成很大压力,成为新的瓶颈,从而使整个系统的性能受到限制。
3.1.2LVS/TUN方式的负载均衡集群
TUN是指IP Tunneling,它的转发流程是:
Director机器收到外界请求,按相应的调度算法,通过IP隧道发送到相应Real Server,Real Server处理完该请求后,将结果数据包直接返回给客户。至此完成一次负载调度。
最简单的LVS/TUN方式的负载均衡集群架构使用IP Tunneling技术,在Director机器和Real Server机器之间架设一个IP Tunnel,通过IP Tunnel将负载分配到Real Server机器上。Director和Real Server之间的关系比较松散,可以是在同一个网络中,也可以是在不同的网络中,只要两者能够通过IP Tunnel相连就行。收到负载分配的Real Server机器处理完后会直接将反馈数据送回给客户,而不必通过Director机器。实际应用中,服务器必须拥有正式的IP地址用于与客户机直接通信,并且所有服务器必须支持IP隧道协议。
该方式中Director将客户请求分配到不同的Real Server,Real Server处理请求后直接回应给用户,这样Director就只处理客户机与服务器的一半连接,极大地提高了Director的调度处理能力,使集群系统能容纳更多的节点数。另外TUN方式中的Real Server可以在任何LAN或WAN上运行,这样可以构筑跨地域的集群,其应对灾难的能力也更强,但是服务器需要为IP封装付出一定的资源开销,而且后端的Real Server必须是支持IP Tunneling的操作系统。
3.3.3LVS/TUN方式的负载均衡集群
DR是指Direct Routing,它的转发流程是:
Director机器收到外界请求,按相应的调度算法将其直接发送到相应Real Server,Real Server处理完该请求后,将结果数据包直接返回给客户,完成一次负载调度。
构架一个最简单的LVS/DR方式的负载均衡集群Real Server和Director都在同一个物理网段中,Director的网卡IP是192.168.0.253,再绑定另一个IP: 192.168.0.254作为对外界的virtual IP,外界客户通过该IP来访问整个集群系统。Real Server在lo上绑定IP:192.168.0.254,同时加入相应的路由。
LVS/DR方式与前面的LVS/TUN方式有些类似,前台的Director机器也是只需要接收和调度外界的请求,而不需要负责返回这些请求的反馈结果,所以能够负载更多的Real Server,提高Director的调度处理能力,使集群系统容纳更多的Real Server。但LVS/DR需要改写请求报文的MAC地址,所以所有服务器必须在同一物理网段内。
3.3架构
LVS架设的服务器集群系统有三个部分组成:最前端的负载均衡层(Loader Balancer),中间的服务器群组层,用Server Array表示,最底层的数据共享存储层,用Shared Storage表示。在用户看来所有的应用都是透明的,用户只是在使用一个虚拟服务器提供的高性能服务。
LVS的体系架构如图:
分布式系统中,应用只部署一台服务器会存在单点故障,负载均衡同样有类似的问题。一般可采用主备或负载均衡设备集群的方式节约单点故障或高并发请求分流。
Ngnix高可用,至少包含两个Ngnix服务器,一台主服务器,一台备服务器,之间使用Keepalived做健康监控和故障检测。开放VIP端口,通过防火墙进行外部映射。
DNS解析公网的IP实际为VIP。
三、LVS负载均衡
LVS是一个开源的软件,由毕业于国防科技大学的章文嵩博士于1998年5月创立,用来实现Linux平台下的简单负载均衡。LVS是Linux Virtual Server的缩写,意思是Linux虚拟服务器。
基于IP层的负载均衡调度技术,它在操作系统核心层上,将来自IP层的TCP/UDP请求均衡地转移到不同的 服务器,从而将一组服务器构成一个高性能、高可用的虚拟服务器。
操作系统:Liunx
开发语言:C
并发性能:默认4096,可以修改但需要重新编译。
3.1.功能
LVS的主要功能是实现IP层(网络层)负载均衡,有NAT,TUN,DR三种请求转发模式。
3.1.1LVS/NAT方式的负载均衡集群
NAT是指Network Address Translation,它的转发流程是:Director机器收到外界请求,改写数据包的目标地址,按相应的调度算法将其发送到相应Real Server上,Real Server处理完该请求后,将结果数据包返回到其默认网关,即Director机器上,Director机器再改写数据包的源地址,最后将其返回给外界。这样就完成一次负载调度。
构架一个最简单的LVS/NAT方式的负载均衡集群Real Server可以是任何的操作系统,而且无需做任何特殊的设定,惟一要做的就是将其默认网关指向Director机器。Real Server可以使用局域网的内部IP(192.168.0.0/24)。Director要有两块网卡,一块网卡绑定一个外部IP地址 (10.0.0.1),另一块网卡绑定局域网的内部IP(192.168.0.254),作为Real Server的默认网关。
LVS/NAT方式实现起来最为简单,而且Real Server使用的是内部IP,可以节省Real IP的开销。但因为执行NAT需要重写流经Director的数据包,在速度上有一定延迟;
当用户的请求非常短,而服务器的回应非常大的情况下,会对Director形成很大压力,成为新的瓶颈,从而使整个系统的性能受到限制。
3.1.2LVS/TUN方式的负载均衡集群
TUN是指IP Tunneling,它的转发流程是:
Director机器收到外界请求,按相应的调度算法,通过IP隧道发送到相应Real Server,Real Server处理完该请求后,将结果数据包直接返回给客户。至此完成一次负载调度。
最简单的LVS/TUN方式的负载均衡集群架构使用IP Tunneling技术,在Director机器和Real Server机器之间架设一个IP Tunnel,通过IP Tunnel将负载分配到Real Server机器上。Director和Real Server之间的关系比较松散,可以是在同一个网络中,也可以是在不同的网络中,只要两者能够通过IP Tunnel相连就行。收到负载分配的Real Server机器处理完后会直接将反馈数据送回给客户,而不必通过Director机器。实际应用中,服务器必须拥有正式的IP地址用于与客户机直接通信,并且所有服务器必须支持IP隧道协议。
该方式中Director将客户请求分配到不同的Real Server,Real Server处理请求后直接回应给用户,这样Director就只处理客户机与服务器的一半连接,极大地提高了Director的调度处理能力,使集群系统能容纳更多的节点数。另外TUN方式中的Real Server可以在任何LAN或WAN上运行,这样可以构筑跨地域的集群,其应对灾难的能力也更强,但是服务器需要为IP封装付出一定的资源开销,而且后端的Real Server必须是支持IP Tunneling的操作系统。
3.3.3LVS/TUN方式的负载均衡集群
DR是指Direct Routing,它的转发流程是:
Director机器收到外界请求,按相应的调度算法将其直接发送到相应Real Server,Real Server处理完该请求后,将结果数据包直接返回给客户,完成一次负载调度。
构架一个最简单的LVS/DR方式的负载均衡集群Real Server和Director都在同一个物理网段中,Director的网卡IP是192.168.0.253,再绑定另一个IP: 192.168.0.254作为对外界的virtual IP,外界客户通过该IP来访问整个集群系统。Real Server在lo上绑定IP:192.168.0.254,同时加入相应的路由。
LVS/DR方式与前面的LVS/TUN方式有些类似,前台的Director机器也是只需要接收和调度外界的请求,而不需要负责返回这些请求的反馈结果,所以能够负载更多的Real Server,提高Director的调度处理能力,使集群系统容纳更多的Real Server。但LVS/DR需要改写请求报文的MAC地址,所以所有服务器必须在同一物理网段内。
3.3架构
LVS架设的服务器集群系统有三个部分组成:最前端的负载均衡层(Loader Balancer),中间的服务器群组层,用Server Array表示,最底层的数据共享存储层,用Shared Storage表示。在用户看来所有的应用都是透明的,用户只是在使用一个虚拟服务器提供的高性能服务。
LVS的体系架构如图:
![]() LVS的各个层次的详细介绍:
Load Balancer层:位于整个集群系统的最前端,有一台或者多台负载调度器(Director Server)组成,LVS模块就安装在Director Server上,而Director的主要作用类似于一个路由器,它含有完成LVS功能所设定的路由表,通过这些路由表把用户的请求分发给Server Array层的应用服务器(Real Server)上。同时,在Director Server上还要安装对Real Server服务的监控模块Ldirectord,此模块用于监测各个Real Server服务的健康状况。在Real Server不可用时把它从LVS路由表中剔除,恢复时重新加入。
Server Array层:由一组实际运行应用服务的机器组成,Real Server可以是WEB服务器、MAIL服务器、FTP服务器、DNS服务器、视频服务器中的一个或者多个,每个Real Server之间通过高速的LAN或分布在各地的WAN相连接。在实际的应用中,Director Server也可以同时兼任Real Server的角色。
Shared Storage层:是为所有Real Server提供共享存储空间和内容一致性的存储区域,在物理上,一般有磁盘阵列设备组成,为了提供内容的一致性,一般可以通过NFS网络文件系统共享数 据,但是NFS在繁忙的业务系统中,性能并不是很好,此时可以采用集群文件系统,例如Red hat的GFS文件系统,oracle提供的OCFS2文件系统等。
从整个LVS结构可以看出,Director Server是整个LVS的核心,目前,用于Director Server的操作系统只能是Linux和FreeBSD,linux2.6内核不用任何设置就可以支持LVS功能,而FreeBSD作为 Director Server的应用还不是很多,性能也不是很好。对于Real Server,几乎可以是所有的系统平台,Linux、windows、Solaris、AIX、BSD系列都能很好的支持。
3.4均衡策略
LVS默认支持八种负载均衡策略,简述如下:
3.4.1.轮询调度(Round Robin)
调度器通过“轮询”调度算法将外部请求按顺序轮流分配到集群中的真实服务器上,它均等地对待每一台服务器,而不管服务器上实际的连接数和系统负载。
3.4.2.加权轮询(Weighted Round Robin)
调度器通过“加权轮询”调度算法根据真实服务器的不同处理能力来调度访问请求。这样可以保证处理能力强的服务器能处理更多的访问流量。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
3.4.3.最少链接(Least Connections)
调度器通过“最少连接”调度算法动态地将网络请求调度到已建立的链接数最少的服务器上。如果集群系统的真实服务器具有相近的系统性能,采用“最小连接”调度算法可以较好地均衡负载。
3.4.4.加权最少链接(Weighted Least Connections)
在集群系统中的服务器性能差异较大的情况下,调度器采用“加权最少链接”调度算法优化负载均衡性能,具有较高权值的服务器将承受较大比例的活动连接负载。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
3.4.5.基于局部性的最少链接(Locality-Based Least Connections)
“基于局部性的最少链接”调度算法是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。该算法根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则用“最少链接” 的原则选出一个可用的服务器,将请求发送到该服务器。
3.4.6.带复制的基于局部性最少链接(Locality-Based Least Connections with Replication)
“带复制的基于局部性最少链接”调度算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。该算法根据请求的目标IP地址找出该目标IP地址对应的服务器组,按“最小连接”原则从服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按“最小连接”原则从这个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。
3.4.7.目标地址散列(Destination Hashing)
“目标地址散列”调度算法根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
3.4.8.源地址散列(Source Hashing)
“源地址散列”调度算法根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
除具备以上负载均衡算法外,还可以自定义均衡策略。
3.5场景
一般作为入口负载均衡或内部负载均衡,结合反向代理服务器使用。相关架构可参考Ngnix场景架构。
4、HaProxy负载均衡
HAProxy也是使用较多的一款负载均衡软件。HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,是免费、快速并且可靠的一种解决方案。特别适用于那些负载特大的web站点。运行模式使得它可以很简单安全的整合到当前的架构中,同时可以保护你的web服务器不被暴露到网络上。
4.1.特点
支持两种代理模式:TCP(四层)和HTTP(七层),支持虚拟主机;
配置简单,支持url检测后端服务器状态;
做负载均衡软件使用,在高并发情况下,处理速度高于nginx;
TCP层多用于Mysql从(读)服务器负载均衡。 (对Mysql进行负载均衡,对后端的DB节点进行检测和负载均衡)
能够补充Nginx的一些缺点比如Session的保持,Cookie引导等工作
4.2.均衡策略
支持四种常用算法:
1.roundrobin:轮询,轮流分配到后端服务器;
2.static-rr:根据后端服务器性能分配;
3.leastconn:最小连接者优先处理;
4.source:根据请求源IP,与Nginx的IP_Hash类似。
LVS的各个层次的详细介绍:
Load Balancer层:位于整个集群系统的最前端,有一台或者多台负载调度器(Director Server)组成,LVS模块就安装在Director Server上,而Director的主要作用类似于一个路由器,它含有完成LVS功能所设定的路由表,通过这些路由表把用户的请求分发给Server Array层的应用服务器(Real Server)上。同时,在Director Server上还要安装对Real Server服务的监控模块Ldirectord,此模块用于监测各个Real Server服务的健康状况。在Real Server不可用时把它从LVS路由表中剔除,恢复时重新加入。
Server Array层:由一组实际运行应用服务的机器组成,Real Server可以是WEB服务器、MAIL服务器、FTP服务器、DNS服务器、视频服务器中的一个或者多个,每个Real Server之间通过高速的LAN或分布在各地的WAN相连接。在实际的应用中,Director Server也可以同时兼任Real Server的角色。
Shared Storage层:是为所有Real Server提供共享存储空间和内容一致性的存储区域,在物理上,一般有磁盘阵列设备组成,为了提供内容的一致性,一般可以通过NFS网络文件系统共享数 据,但是NFS在繁忙的业务系统中,性能并不是很好,此时可以采用集群文件系统,例如Red hat的GFS文件系统,oracle提供的OCFS2文件系统等。
从整个LVS结构可以看出,Director Server是整个LVS的核心,目前,用于Director Server的操作系统只能是Linux和FreeBSD,linux2.6内核不用任何设置就可以支持LVS功能,而FreeBSD作为 Director Server的应用还不是很多,性能也不是很好。对于Real Server,几乎可以是所有的系统平台,Linux、windows、Solaris、AIX、BSD系列都能很好的支持。
3.4均衡策略
LVS默认支持八种负载均衡策略,简述如下:
3.4.1.轮询调度(Round Robin)
调度器通过“轮询”调度算法将外部请求按顺序轮流分配到集群中的真实服务器上,它均等地对待每一台服务器,而不管服务器上实际的连接数和系统负载。
3.4.2.加权轮询(Weighted Round Robin)
调度器通过“加权轮询”调度算法根据真实服务器的不同处理能力来调度访问请求。这样可以保证处理能力强的服务器能处理更多的访问流量。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
3.4.3.最少链接(Least Connections)
调度器通过“最少连接”调度算法动态地将网络请求调度到已建立的链接数最少的服务器上。如果集群系统的真实服务器具有相近的系统性能,采用“最小连接”调度算法可以较好地均衡负载。
3.4.4.加权最少链接(Weighted Least Connections)
在集群系统中的服务器性能差异较大的情况下,调度器采用“加权最少链接”调度算法优化负载均衡性能,具有较高权值的服务器将承受较大比例的活动连接负载。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
3.4.5.基于局部性的最少链接(Locality-Based Least Connections)
“基于局部性的最少链接”调度算法是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。该算法根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则用“最少链接” 的原则选出一个可用的服务器,将请求发送到该服务器。
3.4.6.带复制的基于局部性最少链接(Locality-Based Least Connections with Replication)
“带复制的基于局部性最少链接”调度算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。该算法根据请求的目标IP地址找出该目标IP地址对应的服务器组,按“最小连接”原则从服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按“最小连接”原则从这个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。
3.4.7.目标地址散列(Destination Hashing)
“目标地址散列”调度算法根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
3.4.8.源地址散列(Source Hashing)
“源地址散列”调度算法根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
除具备以上负载均衡算法外,还可以自定义均衡策略。
3.5场景
一般作为入口负载均衡或内部负载均衡,结合反向代理服务器使用。相关架构可参考Ngnix场景架构。
4、HaProxy负载均衡
HAProxy也是使用较多的一款负载均衡软件。HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,是免费、快速并且可靠的一种解决方案。特别适用于那些负载特大的web站点。运行模式使得它可以很简单安全的整合到当前的架构中,同时可以保护你的web服务器不被暴露到网络上。
4.1.特点
支持两种代理模式:TCP(四层)和HTTP(七层),支持虚拟主机;
配置简单,支持url检测后端服务器状态;
做负载均衡软件使用,在高并发情况下,处理速度高于nginx;
TCP层多用于Mysql从(读)服务器负载均衡。 (对Mysql进行负载均衡,对后端的DB节点进行检测和负载均衡)
能够补充Nginx的一些缺点比如Session的保持,Cookie引导等工作
4.2.均衡策略
支持四种常用算法:
1.roundrobin:轮询,轮流分配到后端服务器;
2.static-rr:根据后端服务器性能分配;
3.leastconn:最小连接者优先处理;
4.source:根据请求源IP,与Nginx的IP_Hash类似。
↧
大型网站架构系列:负载均衡详解
↧
[深度学习]读书学习路线
Deep Learning Papers Reading Roadmap
If you are a newcomer to the Deep Learning area, the first question you may have is "Which paper should I start reading from?" Here is a reading roadmap of Deep Learning papers!The roadmap is constructed in accordance with the following four guidelines:
- From outline to detail
- From old to state-of-the-art
- from generic to specific areas
- focus on state-of-the-art
1 Deep Learning History and Basics
1.0 Book
[0] Bengio, Yoshua, Ian J. Goodfellow, and Aaron Courville. "Deep learning." An MIT Press book. (2015). [pdf] (Deep Learning Bible, you can read this book while reading following papers.) ⭐️⭐️⭐️⭐️⭐️1.1 Survey
[1] LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Deep learning." Nature 521.7553 (2015): 436-444. [pdf](Three Giants' Survey) ⭐️⭐️⭐️⭐️⭐️1.2 Deep Belief Network(DBN)(Milestone of Deep Learning Eve)
[2] Hinton, Geoffrey E., Simon Osindero, and Yee-Whye Teh. "A fast learning algorithm for deep belief nets." Neural computation 18.7 (2006): 1527-1554. [pdf](Deep Learning Eve) ⭐️⭐️⭐️ [3] Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. "Reducing the dimensionality of data with neural networks." Science 313.5786 (2006): 504-507. [pdf] (Milestone, Show the promise of deep learning) ⭐️⭐️⭐️1.3 ImageNet Evolution(Deep Learning broke out from here)
[4] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems. 2012. [pdf] (AlexNet, Deep Learning Breakthrough) ⭐️⭐️⭐️⭐️⭐️ [5] Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014). [pdf] (VGGNet,Neural Networks become very deep!) ⭐️⭐️⭐️ [6] Szegedy, Christian, et al. "Going deeper with convolutions." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015. [pdf] (GoogLeNet) ⭐️⭐️⭐️ [7] He, Kaiming, et al. "Deep residual learning for image recognition." arXiv preprint arXiv:1512.03385 (2015). [pdf](ResNet,Very very deep networks, CVPR best paper) ⭐️⭐️⭐️⭐️⭐️1.4 Speech Recognition Evolution
[8] Hinton, Geoffrey, et al. "Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups." IEEE Signal Processing Magazine 29.6 (2012): 82-97. [pdf] (Breakthrough in speech recognition)⭐️⭐️⭐️⭐️ [9] Graves, Alex, Abdel-rahman Mohamed, and Geoffrey Hinton. "Speech recognition with deep recurrent neural networks." 2013 IEEE international conference on acoustics, speech and signal processing. IEEE, 2013. [pdf](RNN)⭐️⭐️⭐️ [10] Graves, Alex, and Navdeep Jaitly. "Towards End-To-End Speech Recognition with Recurrent Neural Networks." ICML. Vol. 14. 2014. [pdf]⭐️⭐️⭐️ [11] Sak, Haşim, et al. "Fast and accurate recurrent neural network acoustic models for speech recognition." arXiv preprint arXiv:1507.06947 (2015). [pdf] (Google Speech Recognition System) ⭐️⭐️⭐️ [12] Amodei, Dario, et al. "Deep speech 2: End-to-end speech recognition in english and mandarin." arXiv preprint arXiv:1512.02595 (2015). [pdf] (Baidu Speech Recognition System) ⭐️⭐️⭐️⭐️ [13] W. Xiong, J. Droppo, X. Huang, F. Seide, M. Seltzer, A. Stolcke, D. Yu, G. Zweig "Achieving Human Parity in Conversational Speech Recognition." arXiv preprint arXiv:1610.05256 (2016). [pdf] (State-of-the-art in speech recognition, Microsoft) ⭐️⭐️⭐️⭐️After reading above papers, you will have a basic understanding of the Deep Learning history, the basic architectures of Deep Learning model(including CNN, RNN, LSTM) and how deep learning can be applied to image and speech recognition issues. The following papers will take you in-depth understanding of the Deep Learning method, Deep Learning in different areas of application and the frontiers. I suggest that you can choose the following papers based on your interests and research direction.
2 Deep Learning Method
2.1 Model
[14] Hinton, Geoffrey E., et al. "Improving neural networks by preventing co-adaptation of feature detectors." arXiv preprint arXiv:1207.0580 (2012). [pdf] (Dropout) ⭐️⭐️⭐️ [15] Srivastava, Nitish, et al. "Dropout: a simple way to prevent neural networks from overfitting." Journal of Machine Learning Research 15.1 (2014): 1929-1958. [pdf] ⭐️⭐️⭐️ [16] Ioffe, Sergey, and Christian Szegedy. "Batch normalization: Accelerating deep network training by reducing internal covariate shift." arXiv preprint arXiv:1502.03167 (2015). [pdf] (An outstanding Work in 2015) ⭐️⭐️⭐️⭐️ [17] Ba, Jimmy Lei, Jamie Ryan Kiros, and Geoffrey E. Hinton. "Layer normalization." arXiv preprint arXiv:1607.06450 (2016). [pdf] (Update of Batch Normalization) ⭐️⭐️⭐️⭐️ [18] Courbariaux, Matthieu, et al. "Binarized Neural Networks: Training Neural Networks with Weights and Activations Constrained to+ 1 or−1." [pdf] (New Model,Fast) ⭐️⭐️⭐️ [19] Jaderberg, Max, et al. "Decoupled neural interfaces using synthetic gradients." arXiv preprint arXiv:1608.05343 (2016). [pdf] (Innovation of Training Method,Amazing Work) ⭐️⭐️⭐️⭐️⭐️ [20] Chen, Tianqi, Ian Goodfellow, and Jonathon Shlens. "Net2net: Accelerating learning via knowledge transfer." arXiv preprint arXiv:1511.05641 (2015). [pdf] (Modify previously trained network to reduce training epochs)⭐️⭐️⭐️ [21] Wei, Tao, et al. "Network Morphism." arXiv preprint arXiv:1603.01670 (2016). [pdf] (Modify previously trained network to reduce training epochs) ⭐️⭐️⭐️2.2 Optimization
[22] Sutskever, Ilya, et al. "On the importance of initialization and momentum in deep learning." ICML (3) 28 (2013): 1139-1147. [pdf] (Momentum optimizer) ⭐️⭐️ [23] Kingma, Diederik, and Jimmy Ba. "Adam: A method for stochastic optimization." arXiv preprint arXiv:1412.6980 (2014). [pdf] (Maybe used most often currently) ⭐️⭐️⭐️ [24] Andrychowicz, Marcin, et al. "Learning to learn by gradient descent by gradient descent." arXiv preprint arXiv:1606.04474 (2016). [pdf] (Neural Optimizer,Amazing Work) ⭐️⭐️⭐️⭐️⭐️ [25] Han, Song, Huizi Mao, and William J. Dally. "Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding." CoRR, abs/1510.00149 2 (2015). [pdf] (ICLR best paper, new direction to make NN running fast,DeePhi Tech Startup) ⭐️⭐️⭐️⭐️⭐️ [26] Iandola, Forrest N., et al. "SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 1MB model size." arXiv preprint arXiv:1602.07360 (2016). [pdf] (Also a new direction to optimize NN,DeePhi Tech Startup)⭐️⭐️⭐️⭐️2.3 Unsupervised Learning / Deep Generative Model
[27] Le, Quoc V. "Building high-level features using large scale unsupervised learning." 2013 IEEE international conference on acoustics, speech and signal processing. IEEE, 2013. [pdf] (Milestone, Andrew Ng, Google Brain Project, Cat) ⭐️⭐️⭐️⭐️ [28] Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes." arXiv preprint arXiv:1312.6114 (2013). [pdf] (VAE) ⭐️⭐️⭐️⭐️ [29] Goodfellow, Ian, et al. "Generative adversarial nets." Advances in Neural Information Processing Systems. 2014. [pdf] (GAN,super cool idea) ⭐️⭐️⭐️⭐️⭐️ [30] Radford, Alec, Luke Metz, and Soumith Chintala. "Unsupervised representation learning with deep convolutional generative adversarial networks." arXiv preprint arXiv:1511.06434 (2015). [pdf] (DCGAN) ⭐️⭐️⭐️⭐️ [31] Gregor, Karol, et al. "DRAW: A recurrent neural network for image generation." arXiv preprint arXiv:1502.04623 (2015). [pdf] (VAE with attention, outstanding work) ⭐️⭐️⭐️⭐️⭐️ [32] Oord, Aaron van den, Nal Kalchbrenner, and Koray Kavukcuoglu. "Pixel recurrent neural networks." arXiv preprint arXiv:1601.06759 (2016). [pdf] (PixelRNN) ⭐️⭐️⭐️⭐️ [33] Oord, Aaron van den, et al. "Conditional image generation with PixelCNN decoders." arXiv preprint arXiv:1606.05328 (2016). [pdf] (PixelCNN) ⭐️⭐️⭐️⭐️2.4 RNN / Sequence-to-Sequence Model
[34] Graves, Alex. "Generating sequences with recurrent neural networks." arXiv preprint arXiv:1308.0850 (2013).[pdf] (LSTM, very nice generating result, show the power of RNN) ⭐️⭐️⭐️⭐️ [35] Cho, Kyunghyun, et al. "Learning phrase representations using RNN encoder-decoder for statistical machine translation." arXiv preprint arXiv:1406.1078 (2014). [pdf] (First Seq-to-Seq Paper) ⭐️⭐️⭐️⭐️ [36] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural networks." Advances in neural information processing systems. 2014. [pdf] (Outstanding Work) ⭐️⭐️⭐️⭐️⭐️ [37] Bahdanau, Dzmitry, KyungHyun Cho, and Yoshua Bengio. "Neural Machine Translation by Jointly Learning to Align and Translate." arXiv preprint arXiv:1409.0473 (2014). [pdf] ⭐️⭐️⭐️⭐️ [38] Vinyals, Oriol, and Quoc Le. "A neural conversational model." arXiv preprint arXiv:1506.05869 (2015). [pdf](Seq-to-Seq on Chatbot) ⭐️⭐️⭐️2.5 Neural Turing Machine
[39] Graves, Alex, Greg Wayne, and Ivo Danihelka. "Neural turing machines." arXiv preprint arXiv:1410.5401 (2014).[pdf] (Basic Prototype of Future Computer) ⭐️⭐️⭐️⭐️⭐️ [40] Zaremba, Wojciech, and Ilya Sutskever. "Reinforcement learning neural Turing machines." arXiv preprint arXiv:1505.00521 362 (2015). [pdf] ⭐️⭐️⭐️ [41] Weston, Jason, Sumit Chopra, and Antoine Bordes. "Memory networks." arXiv preprint arXiv:1410.3916 (2014).[pdf] ⭐️⭐️⭐️ [42] Sukhbaatar, Sainbayar, Jason Weston, and Rob Fergus. "End-to-end memory networks." Advances in neural information processing systems. 2015. [pdf] ⭐️⭐️⭐️⭐️ [43] Vinyals, Oriol, Meire Fortunato, and Navdeep Jaitly. "Pointer networks." Advances in Neural Information Processing Systems. 2015. [pdf] ⭐️⭐️⭐️⭐️ [44] Graves, Alex, et al. "Hybrid computing using a neural network with dynamic external memory." Nature (2016).[pdf] (Milestone,combine above papers' ideas) ⭐️⭐️⭐️⭐️⭐️2.6 Deep Reinforcement Learning
[45] Mnih, Volodymyr, et al. "Playing atari with deep reinforcement learning." arXiv preprint arXiv:1312.5602 (2013). [pdf]) (First Paper named deep reinforcement learning) ⭐️⭐️⭐️⭐️ [46] Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533. [pdf] (Milestone) ⭐️⭐️⭐️⭐️⭐️ [47] Wang, Ziyu, Nando de Freitas, and Marc Lanctot. "Dueling network architectures for deep reinforcement learning." arXiv preprint arXiv:1511.06581 (2015). [pdf] (ICLR best paper,great idea) ⭐️⭐️⭐️⭐️ [48] Mnih, Volodymyr, et al. "Asynchronous methods for deep reinforcement learning." arXiv preprint arXiv:1602.01783 (2016). [pdf] (State-of-the-art method) ⭐️⭐️⭐️⭐️⭐️ [49] Lillicrap, Timothy P., et al. "Continuous control with deep reinforcement learning." arXiv preprint arXiv:1509.02971 (2015). [pdf] (DDPG) ⭐️⭐️⭐️⭐️ [50] Gu, Shixiang, et al. "Continuous Deep Q-Learning with Model-based Acceleration." arXiv preprint arXiv:1603.00748 (2016). [pdf] (NAF) ⭐️⭐️⭐️⭐️ [51] Schulman, John, et al. "Trust region policy optimization." CoRR, abs/1502.05477 (2015). [pdf] (TRPO)⭐️⭐️⭐️⭐️ [52] Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489. [pdf] (AlphaGo) ⭐️⭐️⭐️⭐️⭐️2.7 Deep Transfer Learning / Lifelong Learning / especially for RL
[53] Bengio, Yoshua. "Deep Learning of Representations for Unsupervised and Transfer Learning." ICML Unsupervised and Transfer Learning 27 (2012): 17-36. [pdf] (A Tutorial) ⭐️⭐️⭐️ [54] Silver, Daniel L., Qiang Yang, and Lianghao Li. "Lifelong Machine Learning Systems: Beyond Learning Algorithms." AAAI Spring Symposium: Lifelong Machine Learning. 2013. [pdf] (A brief discussion about lifelong learning) ⭐️⭐️⭐️ [55] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015). [pdf] (Godfather's Work) ⭐️⭐️⭐️⭐️ [56] Rusu, Andrei A., et al. "Policy distillation." arXiv preprint arXiv:1511.06295 (2015). [pdf] (RL domain) ⭐️⭐️⭐️ [57] Parisotto, Emilio, Jimmy Lei Ba, and Ruslan Salakhutdinov. "Actor-mimic: Deep multitask and transfer reinforcement learning." arXiv preprint arXiv:1511.06342 (2015). [pdf] (RL domain) ⭐️⭐️⭐️ [58] Rusu, Andrei A., et al. "Progressive neural networks." arXiv preprint arXiv:1606.04671 (2016). [pdf](Outstanding Work, A novel idea) ⭐️⭐️⭐️⭐️⭐️2.8 One Shot Deep Learning
[59] Lake, Brenden M., Ruslan Salakhutdinov, and Joshua B. Tenenbaum. "Human-level concept learning through probabilistic program induction." Science 350.6266 (2015): 1332-1338. [pdf] (No Deep Learning,but worth reading) ⭐️⭐️⭐️⭐️⭐️ [60] Koch, Gregory, Richard Zemel, and Ruslan Salakhutdinov. "Siamese Neural Networks for One-shot Image Recognition."(2015) [pdf] ⭐️⭐️⭐️ [61] Santoro, Adam, et al. "One-shot Learning with Memory-Augmented Neural Networks." arXiv preprint arXiv:1605.06065 (2016). [pdf] (A basic step to one shot learning) ⭐️⭐️⭐️⭐️ [62] Vinyals, Oriol, et al. "Matching Networks for One Shot Learning." arXiv preprint arXiv:1606.04080 (2016). [pdf]⭐️⭐️⭐️ [63] Hariharan, Bharath, and Ross Girshick. "Low-shot visual object recognition." arXiv preprint arXiv:1606.02819 (2016). [pdf] (A step to large data) ⭐️⭐️⭐️⭐️3 Applications
3.1 NLP(Natural Language Processing)
[1] Antoine Bordes, et al. "Joint Learning of Words and Meaning Representations for Open-Text Semantic Parsing." AISTATS(2012) [pdf] ⭐️⭐️⭐️⭐️ [2] Mikolov, et al. "Distributed representations of words and phrases and their compositionality." ANIPS(2013): 3111-3119 [pdf] (word2vec) ⭐️⭐️⭐️ [3] Sutskever, et al. "“Sequence to sequence learning with neural networks." ANIPS(2014) [pdf] ⭐️⭐️⭐️ [4] Ankit Kumar, et al. "“Ask Me Anything: Dynamic Memory Networks for Natural Language Processing." arXiv preprint arXiv:1506.07285(2015) [pdf] ⭐️⭐️⭐️⭐️ [5] Yoon Kim, et al. "Character-Aware Neural Language Models." NIPS(2015) arXiv preprint arXiv:1508.06615(2015)[pdf] ⭐️⭐️⭐️⭐️ [6] Jason Weston, et al. "Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks." arXiv preprint arXiv:1502.05698(2015) [pdf] (bAbI tasks) ⭐️⭐️⭐️ [7] Karl Moritz Hermann, et al. "Teaching Machines to Read and Comprehend." arXiv preprint arXiv:1506.03340(2015) [pdf] (CNN/DailyMail cloze style questions) ⭐️⭐️ [8] Alexis Conneau, et al. "Very Deep Convolutional Networks for Natural Language Processing." arXiv preprint arXiv:1606.01781(2016) [pdf] (state-of-the-art in text classification) ⭐️⭐️⭐️ [9] Armand Joulin, et al. "Bag of Tricks for Efficient Text Classification." arXiv preprint arXiv:1607.01759(2016)[pdf] (slightly worse than state-of-the-art, but a lot faster) ⭐️⭐️⭐️3.2 Object Detection
[1] Szegedy, Christian, Alexander Toshev, and Dumitru Erhan. "Deep neural networks for object detection." Advances in Neural Information Processing Systems. 2013. [pdf] ⭐️⭐️⭐️ [2] Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014. [pdf] (RCNN) ⭐️⭐️⭐️⭐️⭐️ [3] He, Kaiming, et al. "Spatial pyramid pooling in deep convolutional networks for visual recognition." European Conference on Computer Vision. Springer International Publishing, 2014. [pdf] (SPPNet) ⭐️⭐️⭐️⭐️ [4] Girshick, Ross. "Fast r-cnn." Proceedings of the IEEE International Conference on Computer Vision. 2015. [pdf]⭐️⭐️⭐️⭐️ [5] Ren, Shaoqing, et al. "Faster R-CNN: Towards real-time object detection with region proposal networks." Advances in neural information processing systems. 2015. [pdf] ⭐️⭐️⭐️⭐️ [6] Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." arXiv preprint arXiv:1506.02640 (2015). [pdf] (YOLO,Oustanding Work, really practical) ⭐️⭐️⭐️⭐️⭐️ [7] Liu, Wei, et al. "SSD: Single Shot MultiBox Detector." arXiv preprint arXiv:1512.02325 (2015). [pdf] ⭐️⭐️⭐️3.3 Visual Tracking
[1] Wang, Naiyan, and Dit-Yan Yeung. "Learning a deep compact image representation for visual tracking." Advances in neural information processing systems. 2013. [pdf] (First Paper to do visual tracking using Deep Learning,DLT Tracker) ⭐️⭐️⭐️ [2] Wang, Naiyan, et al. "Transferring rich feature hierarchies for robust visual tracking." arXiv preprint arXiv:1501.04587 (2015). [pdf] (SO-DLT) ⭐️⭐️⭐️⭐️ [3] Wang, Lijun, et al. "Visual tracking with fully convolutional networks." Proceedings of the IEEE International Conference on Computer Vision. 2015. [pdf] (FCNT) ⭐️⭐️⭐️⭐️ [4] Held, David, Sebastian Thrun, and Silvio Savarese. "Learning to Track at 100 FPS with Deep Regression Networks." arXiv preprint arXiv:1604.01802 (2016). [pdf] (GOTURN,Really fast as a deep learning method,but still far behind un-deep-learning methods) ⭐️⭐️⭐️⭐️ [5] Bertinetto, Luca, et al. "Fully-Convolutional Siamese Networks for Object Tracking." arXiv preprint arXiv:1606.09549 (2016). [pdf] (SiameseFC,New state-of-the-art for real-time object tracking) ⭐️⭐️⭐️⭐️ [6] Martin Danelljan, Andreas Robinson, Fahad Khan, Michael Felsberg. "Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking." ECCV (2016) [pdf] (C-COT) ⭐️⭐️⭐️⭐️ [7] Nam, Hyeonseob, Mooyeol Baek, and Bohyung Han. "Modeling and Propagating CNNs in a Tree Structure for Visual Tracking." arXiv preprint arXiv:1608.07242 (2016). [pdf] (VOT2016 Winner,TCNN) ⭐️⭐️⭐️⭐️3.4 Image Caption
[1] Farhadi,Ali,etal. "Every picture tells a story: Generating sentences from images". In Computer VisionECCV 2010. Springer Berlin Heidelberg:15-29, 2010. [pdf] ⭐️⭐️⭐️ [2] Kulkarni, Girish, et al. "Baby talk: Understanding and generating image descriptions". In Proceedings of the 24th CVPR, 2011. [pdf]⭐️⭐️⭐️⭐️ [3] Vinyals, Oriol, et al. "Show and tell: A neural image caption generator". In arXiv preprint arXiv:1411.4555, 2014.[pdf]⭐️⭐️⭐️ [4] Donahue, Jeff, et al. "Long-term recurrent convolutional networks for visual recognition and description". In arXiv preprint arXiv:1411.4389 ,2014. [pdf] [5] Karpathy, Andrej, and Li Fei-Fei. "Deep visual-semantic alignments for generating image descriptions". In arXiv preprint arXiv:1412.2306, 2014. [pdf]⭐️⭐️⭐️⭐️⭐️ [6] Karpathy, Andrej, Armand Joulin, and Fei Fei F. Li. "Deep fragment embeddings for bidirectional image sentence mapping". In Advances in neural information processing systems, 2014. [pdf]⭐️⭐️⭐️⭐️ [7] Fang, Hao, et al. "From captions to visual concepts and back". In arXiv preprint arXiv:1411.4952, 2014.[pdf]⭐️⭐️⭐️⭐️⭐️ [8] Chen, Xinlei, and C. Lawrence Zitnick. "Learning a recurrent visual representation for image caption generation". In arXiv preprint arXiv:1411.5654, 2014. [pdf]⭐️⭐️⭐️⭐️ [9] Mao, Junhua, et al. "Deep captioning with multimodal recurrent neural networks (m-rnn)". In arXiv preprint arXiv:1412.6632, 2014. [pdf]⭐️⭐️⭐️ [10] Xu, Kelvin, et al. "Show, attend and tell: Neural image caption generation with visual attention". In arXiv preprint arXiv:1502.03044, 2015. [pdf]⭐️⭐️⭐️⭐️⭐️3.5 Machine Translation
Some milestone papers are listed in RNN / Seq-to-Seq topic.[1] Luong, Minh-Thang, et al. "Addressing the rare word problem in neural machine translation." arXiv preprint arXiv:1410.8206 (2014). [pdf] ⭐️⭐️⭐️⭐️ [2] Sennrich, et al. "Neural Machine Translation of Rare Words with Subword Units". In arXiv preprint arXiv:1508.07909, 2015. [pdf]⭐️⭐️⭐️ [3] Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. "Effective approaches to attention-based neural machine translation." arXiv preprint arXiv:1508.04025 (2015). [pdf] ⭐️⭐️⭐️⭐️ [4] Chung, et al. "A Character-Level Decoder without Explicit Segmentation for Neural Machine Translation". In arXiv preprint arXiv:1603.06147, 2016. [pdf]⭐️⭐️ [5] Lee, et al. "Fully Character-Level Neural Machine Translation without Explicit Segmentation". In arXiv preprint arXiv:1610.03017, 2016. [pdf]⭐️⭐️⭐️⭐️⭐️ [6] Wu, Schuster, Chen, Le, et al. "Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation". In arXiv preprint arXiv:1609.08144v2, 2016. [pdf] (Milestone) ⭐️⭐️⭐️⭐️
3.6 Robotics
[1] Koutník, Jan, et al. "Evolving large-scale neural networks for vision-based reinforcement learning." Proceedings of the 15th annual conference on Genetic and evolutionary computation. ACM, 2013. [pdf] ⭐️⭐️⭐️ [2] Levine, Sergey, et al. "End-to-end training of deep visuomotor policies." Journal of Machine Learning Research 17.39 (2016): 1-40. [pdf] ⭐️⭐️⭐️⭐️⭐️ [3] Pinto, Lerrel, and Abhinav Gupta. "Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours." arXiv preprint arXiv:1509.06825 (2015). [pdf] ⭐️⭐️⭐️ [4] Levine, Sergey, et al. "Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection." arXiv preprint arXiv:1603.02199 (2016). [pdf] ⭐️⭐️⭐️⭐️ [5] Zhu, Yuke, et al. "Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning." arXiv preprint arXiv:1609.05143 (2016). [pdf] ⭐️⭐️⭐️⭐️ [6] Yahya, Ali, et al. "Collective Robot Reinforcement Learning with Distributed Asynchronous Guided Policy Search." arXiv preprint arXiv:1610.00673 (2016). [pdf] ⭐️⭐️⭐️⭐️ [7] Gu, Shixiang, et al. "Deep Reinforcement Learning for Robotic Manipulation." arXiv preprint arXiv:1610.00633 (2016). [pdf] ⭐️⭐️⭐️⭐️ [8] A Rusu, M Vecerik, Thomas Rothörl, N Heess, R Pascanu, R Hadsell."Sim-to-Real Robot Learning from Pixels with Progressive Nets." arXiv preprint arXiv:1610.04286 (2016). [pdf] ⭐️⭐️⭐️⭐️3.7 Art
[1] Mordvintsev, Alexander; Olah, Christopher; Tyka, Mike (2015). "Inceptionism: Going Deeper into Neural Networks". Google Research. [html] (Deep Dream) ⭐️⭐️⭐️⭐️ [2] Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. "A neural algorithm of artistic style." arXiv preprint arXiv:1508.06576 (2015). [pdf] (Outstanding Work, most successful method currently) ⭐️⭐️⭐️⭐️⭐️ [3] Zhu, Jun-Yan, et al. "Generative Visual Manipulation on the Natural Image Manifold." European Conference on Computer Vision. Springer International Publishing, 2016. [pdf] (iGAN) ⭐️⭐️⭐️⭐️ [4] Champandard, Alex J. "Semantic Style Transfer and Turning Two-Bit Doodles into Fine Artworks." arXiv preprint arXiv:1603.01768 (2016). [pdf] (Neural Doodle) ⭐️⭐️⭐️⭐️ [5] Zhang, Richard, Phillip Isola, and Alexei A. Efros. "Colorful Image Colorization." arXiv preprint arXiv:1603.08511 (2016). [pdf] ⭐️⭐️⭐️⭐️ [6] Johnson, Justin, Alexandre Alahi, and Li Fei-Fei. "Perceptual losses for real-time style transfer and super-resolution." arXiv preprint arXiv:1603.08155 (2016). [pdf] ⭐️⭐️⭐️⭐️3.8 Audio
3.9 Game
3.10 Knowledge Graph
3.11 Recommender Systems
3.12 Bioinformatics / Computational Biology
3.13 Neural Network Chip
3.14 Other Frontiers
↧
↧
分布式服务框架dubbo原理解析
alibaba有好几个分布式框架,主要有:进行远程调用(类似于RMI的这种远程调用)的(dubbo、hsf),jms消息服务(napoli、notify),KV数据库(tair)等。这个框架/工具/产品在实现的时候,都考虑到了容灾,扩展,负载均衡,于是出现一个配置中心(ConfigServer)的东西来解决这些问题。
基本原理如图:

在我们的系统中,经常会有一些跨系统的调用,如在A系统中要调用B系统的一个服务,我们可能会使用RMI直接来进行,B系统发布一个RMI接口服务,然后A系统就来通过RMI调用这个接口,为了解决容灾,扩展,负载均衡的问题,我们可能会想很多办法,alibaba的这个办法感觉不错。
本文只说dubbo,原理如下:
- ConfigServer
| serviceName | serverAddressList | clientAddressList |
| UserService | 192.168.0.1,192.168.0.2,192.168.0.3,192.168.0.4 | 172.16.0.1,172.16.0.2 |
| ProductService | 192.168.0.3,192.168.0.4,192.168.0.5,192.168.0.6 | 172.16.0.2,172.16.0.3 |
| OrderService | 192.168.0.10,192.168.0.12,192.168.0.5,192.168.0.6 | 172.16.0.3,172.16.0.4 |
当某个Server不可用,那么就更新受影响的服务对应的serverAddressList,即把这个Server从serverAddressList中踢出去(从地址列表中删除),同时将推送serverAddressList给这些受影响的服务的clientAddressList里面的所有Client。如:192.168.0.3挂了,那么UserService和ProductService的serverAddressList都要把192.168.0.3删除掉,同时把新的列表告诉对应的Client 172.16.0.1,172.16.0.2,172.16.0.3;
当某个Client挂了,那么更新受影响的服务对应的clientAddressList
ConfigServer根据服务列表,就能提供一个web管理界面,来查看管理服务的提供者和使用者。
新加一个Server时,由于它会主动与ConfigServer取得联系,而ConfigServer又会将这个信息主动发送给Client,所以新加一个Server时,只需要启动Server,然后几秒钟内,Client就会使用上它提供的服务
- Client
Client在使用服务的时候根据服务名称去ConfigServer中获取服务提供者信息(这样ConfigServer就知道某个服务是当前哪几个Client在使用),Client拿到这些服务提供者信息后,与它们都建立连接,后面就可以直接调用服务了,当有多个服务提供者的时候,Client根据一定的规则来进行负载均衡,如轮询,随机,按权重等。
一旦Client使用的服务它对应的服务提供者有变化(服务提供者有新增,删除的情况),ConfigServer就会把最新的服务提供者列表推送给Client,Client就会依据最新的服务提供者列表重新建立连接,新增的提供者建立连接,删除的提供者丢弃连接
- Server
优点:
1,只要在Client和Server启动的时候,ConfigServer是好的,服务就可调用了,如果后面ConfigServer挂了,那只影响ConfigServer挂了以后服务提供者有变化,而Client还无法感知这一变化。
2,Client每次调用服务是不经过ConfigServer的,Client只是与它建立联系,从它那里获取提供服务者列表而已
3,调用服务-负载均衡:Client调用服务时,可以根据规则在多个服务提供者之间轮流调用服务。
4,服务提供者-容灾:某一个Server挂了,Client依然是可以正确的调用服务的,当前提是这个服务有至少2个服务提供者,Client能很快的感知到服务提供者的变化,并作出相应反应。
5,服务提供者-扩展:添加一个服务提供者很容易,而且Client会很快的感知到它的存在并使用它。
顺便说一下,hadoop里面的中心节点跟这里的configServer作用类似,在维护节点列表方面,不过它的相关计算都需要通过中心节节点,让它来分配任务。
↧
[Yol出品]也说单例模式
在GoF的23种设计模式中,单例模式是比较简单的一种。然而,有时候越是简单的东西越容易出现问题。下面就单例设计模式详细的探讨一下。
所谓单例模式,简单来说,就是在整个应用中保证只有一个类的实例存在。就像是Java Web中的application,也就是提供了一个全局变量,用处相当广泛,比如保存全局数据,实现全局性的操作等。
1. 最简单的实现
首先,能够想到的最简单的实现是,把类的构造函数写成private的,从而保证别的类不能实例化此类,然后在类中提供一个静态的实例并能够返回给使用者。这样,使用者就可以通过这个引用使用到这个类的实例了。
public class SingletonClass {
private static final SingletonClass instance = new SingletonClass();
public static SingletonClass getInstance() {
return instance;
}
private SingletonClass() {
}
}
如上例,外部使用者如果需要使用SingletonClass的实例,只能通过getInstance()方法,并且它的构造方法是private的,这样就保证了只能有一个对象存在。
2. 性能优化——lazy loaded
上面的代码虽然简单,但是有一个问题——无论这个类是否被使用,都会创建一个instance对象。如果这个创建过程很耗时,比如需要连接10000次数据库(夸张了…:-)),并且这个类还并不一定会被使用,那么这个创建过程就是无用的。怎么办呢?
为了解决这个问题,我们想到了新的解决方案:
public class SingletonClass {
private static SingletonClass instance = null;
public static SingletonClass getInstance() {
if(instance == null) {
instance = new SingletonClass();
}
return instance;
}
private SingletonClass() {
}
}
代码的变化有两处——首先,把instance初始化为null,直到第一次使用的时候通过判断是否为null来创建对象。因为创建过程不在声明处,所以那个final的修饰必须去掉。
我们来想象一下这个过程。要使用SingletonClass,调用getInstance()方法。第一次的时候发现instance是null,然后就新建一个对象,返回出去;第二次再使用的时候,因为这个instance是static的,所以已经不是null了,因此不会再创建对象,直接将其返回。
这个过程就成为lazy loaded,也就是迟加载——直到使用的时候才进行加载。
3. 同步
上面的代码很清楚,也很简单。然而就像那句名言:“80%的错误都是由20%代码优化引起的”。单线程下,这段代码没有什么问题,可是如果是多线程,麻烦就来了。我们来分析一下:
线程A希望使用SingletonClass,调用getInstance()方法。因为是第一次调用,A就发现instance是null的,于是它开始创建实例,就在这个时候,CPU发生时间片切换,线程B开始执行,它要使用SingletonClass,调用getInstance()方法,同样检测到instance是null——注意,这是在A检测完之后切换的,也就是说A并没有来得及创建对象——因此B开始创建。B创建完成后,切换到A继续执行,因为它已经检测完了,所以A不会再检测一遍,它会直接创建对象。这样,线程A和B各自拥有一个SingletonClass的对象——单例失败!
解决的方法也很简单,那就是加锁:
public class SingletonClass {
private static SingletonClass instance = null;
public synchronized static SingletonClass getInstance() {
if(instance == null) {
instance = new SingletonClass();
}
return instance;
}
private SingletonClass() {
}
}
是要getInstance()加上同步锁,一个线程必须等待另外一个线程创建完成后才能使用这个方法,这就保证了单例的唯一性。
4. 又是性能
上面的代码又是很清楚很简单的,然而,简单的东西往往不够理想。这段代码毫无疑问存在性能的问题——synchronized修饰的同步块可是要比一般的代码段慢上几倍的!如果存在很多次getInstance()的调用,那性能问题就不得不考虑了!
让我们来分析一下,究竟是整个方法都必须加锁,还是仅仅其中某一句加锁就足够了?我们为什么要加锁呢?分析一下出现lazy loaded的那种情形的原因。原因就是检测null的操作和创建对象的操作分离了。如果这两个操作能够原子地进行,那么单例就已经保证了。于是,我们开始修改代码:
public class SingletonClass {
private static SingletonClass instance = null;
public static SingletonClass getInstance() {
synchronized (SingletonClass.class) {
if(instance == null) {
instance = new SingletonClass();
}
}
return instance;
}
private SingletonClass() {
}
}
首先去掉getInstance()的同步操作,然后把同步锁加载if语句上。但是这样的修改起不到任何作用:因为每次调用getInstance()的时候必然要同步,性能问题还是存在。如果……如果我们事先判断一下是不是为null再去同步呢?
5 读写分离
public class SingletonClass {
private static SingletonClass instance = null;
public static SingletonClass getInstance() {
if (instance == null) {
synchronized (SingletonClass.class) {
if (instance == null) {
instance = new SingletonClass();
}
}
}
return instance;
}
private SingletonClass() {
}
}
还有问题吗?首先判断instance是不是为null,如果为null,加锁初始化;如果不为null,直接返回instance。
这就是double-checked locking设计实现单例模式。到此为止,一切都很完美。我们用一种很聪明的方式实现了单例模式。
↧
[mysql]启动报错:MySQL Daemon failed to start. File ‘./ibtmp1’ size is now 12 MB.
启动mysql 一直报错如下
[crayon-581da6d31a1f7108686526/]
查看mysql日志
[crayon-581da6d31a201870114158/]
注意到里面有句话
[crayon-581da6d31a207870626864/]
意思原来是磁盘full了,
df -h 一看,果然
所以准备清理mysql日志,这时候因mysql是down的,所以无法使用mysql命令清除
找到bin日志所在
通过vim /etc/my.inf查看 binlog的配置路径
[crayon-581da6d31a20d059797927/]
切换到此目录,进行rm -rf binlog.xxx进行有所保留的删除即可~
↧
↧
[Java][集合总结]Collection List Set Map 是否有序及原因一语道破天机
1.Collection List Set Map 区别记忆
这些都代表了Java中的集合,这里主要从其元素是否有序,是否可重复来进行区别记忆,以便恰当地使用,当然还存在同步方面的差异,见上一篇相关文章。
List接口对Collection进行了简单的扩充,它的具体实现类常用的有ArrayList和LinkedList。你可以将任何东西放到一个List容器中,并在需要时从中取出。ArrayList从其命名中可以看出它是一种类似数组的形式进行存储,因此它的随机访问速度极快,而LinkedList的内部实现是链表,它适合于在链表中间需要频繁进行插入和删除操作。在具体应用时可以根据需要自由选择。前面说的Iterator只能对容器进行向前遍历,而ListIterator则继承了Iterator的思想,并提供了对List进行双向遍历的方法。
Set接口也是Collection的一种扩展,而与List不同的时,在Set中的对象元素不能重复,也就是说你不能把同样的东西两次放入同一个Set容器中。它的常用具体实现有HashSet和TreeSet类。HashSet能快速定位一个元素,但是你放到HashSet中的对象需要实现hashCode()方法,它使用了前面说过的哈希码的算法。而TreeSet则将放入其中的元素按序存放,这就要求你放入其中的对象是可排序的,这就用到了集合框架提供的另外两个实用类Comparable和Comparator。一个类是可排序的,它就应该实现Comparable接口。有时多个类具有相同的排序算法,那就不需要在每分别重复定义相同的排序算法,只要实现Comparator接口即可。集合框架中还有两个很实用的公用类:Collections和Arrays。Collections提供了对一个Collection容器进行诸如排序、复制、查找和填充等一些非常有用的方法,Arrays则是对一个数组进行类似的操作。
Map是一种把键对象和值对象进行关联的容器,而一个值对象又可以是一个Map,依次类推,这样就可形成一个多级映射。对于键对象来说,像Set一样,一个Map容器中的键对象不允许重复,这是为了保持查找结果的一致性;如果有两个键对象一样,那你想得到那个键对象所对应的值对象时就有问题了,可能你得到的并不是你想的那个值对象,结果会造成混乱,所以键的唯一性很重要,也是符合集合的性质的。当然在使用过程中,某个键所对应的值对象可能会发生变化,这时会按照最后一次修改的值对象与键对应。对于值对象则没有唯一性的要求。你可以将任意多个键都映射到一个值对象上,这不会发生任何问题(不过对你的使用却可能会造成不便,你不知道你得到的到底是那一个键所对应的值对象)。Map有两种比较常用的实现:HashMap和TreeMap。HashMap也用到了哈希码的算法,以便快速查找一个键,TreeMap则是对键按序存放,因此它便有一些扩展的方法,比如firstKey(),lastKey()等,你还可以从TreeMap中指定一个范围以取得其子Map。键和值的关联很简单,用pub(Object key,Object value)方法即可将一个键与一个值对象相关联。用get(Object key)可得到与此key对象所对应的值对象。
2.List、vector、set、map的区别与联系
| 有序否 | 允许元素重复否 | ||
| Collection | 否 | 是 | |
| List | 是 | 是 | |
| Set | AbstractSet | 否 | 否(原因是hashcode) |
| HashSet | |||
| TreeSet | 是(用二叉树排序) | ||
| Map | AbstractMap | 否 | 使用key-value来映射和存储数据,Key必须惟一,value可以重复 |
| HashMap | |||
| TreeMap | 是(用二叉树排序) | ||
在使用Java的时候,我们都会遇到使用集合(Collection)的时候,但是Java API提供了多种集合的实现,我在使用和面试的时候频频遇到这样的“抉择” 。 :)(主要还是面试的时候)
久而久之,也就有了一点点的心得体会,写出来以供大家讨论。
总的说来,Java API中所用的集合类,都是实现了Collection接口,他的一个类继承结构如下:
Collection<--List<--Vector
Collection<--List<--ArrayList
Collection<--List<--LinkedList
Collection<--Set<--HashSet
Collection<--Set<--HashSet<--LinkedHashSet
Collection<--Set<--SortedSet<--TreeSetVector : 基于Array的List,其实就是封装了Array所不具备的一些功能方便我们使用,它不可能走入Array的限制。性能也就不可能超越Array。所以,在可能的情况下,我们要多运用Array。另外很重要的一点就是Vector“sychronized”的,这个也是Vector和ArrayList的唯一的区别。
ArrayList:同Vector一样是一个基于Array上的链表,但是不同的是ArrayList不是同步的。所以在性能上要比Vector优越一些,但是当运行到多线程环境中时,可需要自己在管理线程的同步问题。
LinkedList:LinkedList不同于前面两种List,它不是基于Array的,所以不受Array性能的限制。它每一个节点(Node)都包含两方面的内容:1.节点本身的数据(data);2.下一个节点的信息(nextNode)。所以当对LinkedList做添加,删除动作的时候就不用像基于Array的List一样,必须进行大量的数据移动。只要更改nextNode的相关信息就可以实现了。这就是LinkedList的优势。
List总结:
1. 所有的List中只能容纳单个不同类型的对象组成的表,而不是Key-Value键值对。例如:[ tom,1,c ];
2. 所有的List中可以有相同的元素,例如Vector中可以有 [ tom,koo,too,koo ];
3. 所有的List中可以有null元素,例如[ tom,null,1 ];
4. 基于Array的List(Vector,ArrayList)适合查询,而LinkedList(链表)适合添加,删除操作。
HashSet:虽然Set同List都实现了Collection接口,但是他们的实现方式却大不一样。List基本上都是以Array为基础。但是Set则是在HashMap的基础上来实现的,这个就是Set和List的根本区别。HashSet的存储方式是把HashMap中的Key作为Set的对应存储项。看看HashSet的add(Object obj)方法的实现就可以一目了然了。
public boolean add(Object obj)
{
return map.put(obj, PRESENT) == null;
}
这个也是为什么在Set中不能像在List中一样有重复的项的根本原因,因为HashMap的key是不能有重复的。
LinkedHashSet:HashSet的一个子类,一个链表。
TreeSet:SortedSet的子类,它不同于HashSet的根本就是TreeSet是有序的。它是通过SortedMap来实现的。
Set总结:
1. Set实现的基础是Map(HashMap);
2. Set中的元素是不能重复的,如果使用add(Object obj)方法添加已经存在的对象,则会覆盖前面的对象;
3.Java基本概念:集合类 List/Set/Map... 的区别和联系
Collection:List、Set
Map:HashMap、HashTable
如何在它们之间选择
一、Array , Arrays
Java所有“存储及随机访问一连串对象”的做法,array是最有效率的一种。
1、
效率高,但容量固定且无法动态改变。
array还有一个缺点是,无法判断其中实际存有多少元素,length只是告诉我们array的容量。
2、Java中有一个Arrays类,专门用来操作array。
arrays中拥有一组static函数,
equals():比较两个array是否相等。array拥有相同元素个数,且所有对应元素两两相等。
fill():将值填入array中。
sort():用来对array进行排序。
binarySearch():在排好序的array中寻找元素。
System.arraycopy():array的复制。
二、Collection , Map
若撰写程序时不知道究竟需要多少对象,需要在空间不足时自动扩增容量,则需要使用容器类库,array不适用。
1、Collection 和 Map 的区别
容器内每个为之所存储的元素个数不同。
Collection类型者,每个位置只有一个元素。
Map类型者,持有 key-value pair,像个小型数据库。
2、各自旗下的子类关系
Collection --List: 将以特定次序存储元素。所以取出来的顺序可能和放入顺序不同。
--ArrayList / LinkedList / Vector --Set : 不能含有重复的元素
--HashSet / TreeSet
Map
--HashMap
--HashTable
--TreeMap
3、其他特征
* List,Set,Map将持有对象一律视为Object型别。
* Collection、List、Set、Map都是接口,不能实例化。
继承自它们的 ArrayList, Vector, HashTable, HashMap是具象class,这些才可被实例化。
* vector容器确切知道它所持有的对象隶属什么型别。vector不进行边界检查。
三、Collections
Collections是针对集合类的一个帮助类。提供了一系列静态方法实现对各种集合的搜索、排序、线程完全化等操作。
相当于对Array进行类似操作的类——Arrays。
如,Collections.max(Collection coll); 取coll中最大的元素。
Collections.sort(List list); 对list中元素排序
四、如何选择?
1、容器类和Array的区别、择取
* 容器类仅能持有对象引用(指向对象的指针),而不是将对象信息copy一份至数列某位置。
* 一旦将对象置入容器内,便损失了该对象的型别信息。
2、
* 在各种Lists中,最好的做法是以ArrayList作为缺省选择。当插入、删除频繁时,使用LinkedList();
Vector总是比ArrayList慢,所以要尽量避免使用。
* 在各种Sets中,HashSet通常优于HashTree(插入、查找)。只有当需要产生一个经过排序的序列,才用TreeSet。
HashTree存在的唯一理由:能够维护其内元素的排序状态。
* 在各种Maps中
HashMap用于快速查找。
* 当元素个数固定,用Array,因为Array效率是最高的。
结论:最常用的是ArrayList,HashSet,HashMap,Array。
注意:
1、Collection没有get()方法来取得某个元素。只能通过iterator()遍历元素。
2、Set和Collection拥有一模一样的接口。
3、List,可以通过get()方法来一次取出一个元素。使用数字来选择一堆对象中的一个,get(0)...。(add/get)
4、一般使用ArrayList。用LinkedList构造堆栈stack、队列queue。
5、Map用 put(k,v) / get(k),还可以使用containsKey()/containsValue()来检查其中是否含有某个key/value。
HashMap会利用对象的hashCode来快速找到key。
* hashing 哈希码就是将对象的信息经过一些转变形成一个独一无二的int值,这个值存储在一个array中。
我们都知道所有存储结构中,array查找速度是最快的。所以,可以加速查找。
发生碰撞时,让array指向多个values。即,数组每个位置上又生成一个梿表。
6、Map中元素,可以将key序列、value序列单独抽取出来。使用keySet()抽取key序列,将map中的所有keys生成一个Set。
使用values()抽取value序列,将map中的所有values生成一个Collection。
为什么一个生成Set,一个生成Collection?那是因为,key总是独一无二的,value允许重复。
↧
[算法][算法性能]各大排序算法性能比较
↧
[排序算法]图解插入排序–直接插入排序
本文:http://www.paymoon.com:8001/index.php/2016/11/03/insertsort/
排序思路:每次将一个待排序的元素与已排序的元素进行逐一比较,直到找到合适的位置按大小插入。
第一趟比较示图:

算法实现:
[crayon-581da6d3196a8203864877/]
结果:
[crayon-581da6d3196bf918790549/]
算法分析:1.当元素的初始序列为正序时,仅外循环要进行n-1趟排序且每一趟只进行一次比较,没有进入if语句不存在元素之间的交换(移动)。此时比较次数(Cmin)和移动次数(Mmin)达到 最小值。
Cmin = n-1 Mmin = 0;
此时时间复杂度为O(n)。
2.当元素的初始序列为反序时,每趟排序中待插入的元素都要和[0,i-1]中的i个元素进行比较且要将这i个元素后移(arr[j+1] = arr[j]),i个元素后移移动次数当然也就为i 了,再加上temp = arr[i]与arr[j+1] = temp的两次移动,每趟移动的次数为i+2,此时比较次数(Cmin)和移动次数(Mmin)达到最小值。
Cmax = 1+2+...+(n-1) = n*(n-1)/2 = O(n2)
Mmax = (1+2)+(2+2)+...+(n-1+2) = (n-1)*(n+4)/2 = O(n2) (i取值范围1~n-1)
此时时间复杂度为O(n2)。
3.在直接插入排序中只使用了i,j,temp这3个辅助元素,与问题规模无关,所以空间复杂度为O(1).
4.在整个排序结束后,即使有相同元素它们的相对位置也没有发生变化,
如:5,3,2,3排序过程如下
A--3,5,2,3
B--2,3,5,3
C--2,3,3,5
排序结束后两个元素3的相对位置没有发生改变,所以直接插入排序是一种稳定排序
原文:http://www.cnblogs.com/MOBIN/p/4679208.html
本文:http://www.paymoon.com:8001/index.php/2016/11/03/insertsort/
↧
[摘抄]序言 谷歌的“痴心妄想”&基本物理原则[first principle and real-world physics]
年少时,第一次考虑到自己的未来,我决心要么当个教授,要么就创建自己的公司。我觉 得,这两种职业都可以给我足够的自主权,让我自由地从基本物理原则出发思考问题,而不 必去迎合那些所谓的“世俗智慧”。
就像埃里克和乔纳森在本书中所说的,在谷歌,我们试着将这种自主思维方式推行到企业的 方方面面。这种思维方式推动了我们公司最伟大的成功,也导致过一些惨痛的失败。实际 上,谷歌就是基于基本物理原则起步的。一天晚上,我做了一个梦(不是梦想,是真实的 梦),醒来后我想:我们能不能把整个互联网上的内容都下载下来,然后只保留链接呢?我 找了一支笔,把细节信息写下来,想看看这个构想到底有没有实现的可能。当时,我压根儿 也没有想过要建立什么搜索引擎。这之后又过了一段时间,我和谢尔盖才意识到通过链接来 为网页排序会大大地优化搜索结果。除此之外,谷歌电子邮箱Gmail也是在这样的“痴心妄 想”中诞生的。10年前,安迪·鲁宾(Andy Rubin)开发安卓系统时,大多数人也都觉得手机行 业与开源操作系统的融合简直是痴人说梦。
随着时间的推移,我意识到,实际上,想要点燃团队的熊熊野心是极其困难的。大多数人并 没有接触过这种如登月般异想天开的思维方式,他们习惯用“不可能”来否定自己的想法,而不 是从基本物理原则出发去探索可能性。正因如此,谷歌才会投入大量精力去物色善于独立思 考的人,并设定远大的目标。因为只要有了合适的人才和足够远大的梦想,你的目标往往就 可以实现。就算跌倒了,你也很可能会从失败中得到宝贵的教训。
不少企业安于现状,只求渐变,不求突破。如果只求渐变,时间一长,企业就会逐渐落伍, 科技行业尤其如此,因为外界改变通常是革命性的,而不是循序渐进的。所以,你需要强迫 自己着眼于未来。也是因此,谷歌才会投资无人驾驶汽车以及“热气球互联网计划”等看似高风 险的领域。现在说来或许有些难以想象,但当我们第一次提出谷歌地图的构想时,人们觉得 我们制作全球地图以及为所有街道拍摄照片的构想是无法实现的。如果说历史可以照见未 来,那么今天看似最冒险的赌注放在几年之后看也就不会显得那么疯狂了。
我个人认为,以上几条原则非常重要,本书中还会谈到更多原则。希望你们能够接受这些想 法,也向不可能发出挑战!
↧
↧
什么才是演讲的“基本物理原则”?what is speaking first principle and real-world physics
Google联合创始人Larry Page为Eric Schmidt的著作“How Google Works”写了序言。开头写了一句很重要的话:
…… 从基本物理原则出发思考问题,不必迎合那些“世俗智慧”。
(…… think form first principle and real-world physics rather than having to accept the prevailing “wisdom”. )
我的学员很多都是创意精英。他们是工程师、产品经理和技术专家,或者是这样出身的高级经理人。
在演讲这件事上,创意精英们不会考虑“世俗智慧”。他们不会在自己的职业能力之上,鲁莽地嫁接一个打鸡血型的演讲技能,或者附上一个成功学口才大师的精神附体。因为这些东西本身就是笑柄,与创意精英内在的品性完全相悖。
创意精英对这些“世俗智慧”的排斥反应是先天的。所以,他们不会崇拜口才大师的江湖经验,也不会迷信成功学的街头智慧。甚至一个带着师爷气的培训师,都不会被他们邀请去上课。
可是话说回来,什么才是演讲的“基本物理原则”?
这个问题在扣问这个行当的本质,也在考验从业老师的理解力。这个问题我已经思考了很长一段时间,也未能得到满意的答案。以下,只是我这个阶段的想法:
- 演讲不只是个物,它还是一个过程。要理解这个过程的动态性和演进性。
- 要为过程设计一个策略。策略必须朴素而真实,它从根本上来自于你看待和对待听众的方式。
- 演讲是对讲者和观众这二者之间某种关系的处理。所以,演讲具有很多二元性的特征,演讲方法有很多双重的策略。
- 严格考察你的动机和对听众的价值。你从前者出发,最终到达后者。
- 演讲是由演讲者和听众共同完成的。
- 知彼解己(First to understand, then to understood)。达到这个状态,才可以享受演讲的美好。
- 理解情境(Context)。演讲的情境之中,最重要的要素是:谁来听?他们因何来听?听完之后他们能怎样?你想讲什么?注意:“你想讲什么”这个放在最后,是故意的,也是必须的。
- 除了逻辑严密、思路清晰、表达准确之外,还要考虑和观众的情感互动。
- 演讲是视听多维度的一种体验。视听多个信息通道的设计和安排,具有艺术性。
- 相比其他的独立技能,演讲能力更为综合。
这有点晦涩?是的。“基本物理原则”不一定好理解,每个还需要解析。这个清单还会增加或者改写,我更希望它能变短。这仅仅是我理解的“基本物理原则”,它除了指导我的工作,也可以给你中肯的提醒:
请找到你的“基本物理原则”。-- gary_yang
↧
重读《资本论》:马克思到底在说什么?
重读《资本论》:马克思到底在说什么?
来源:财经微信号 作者:弗雷德里克·杰姆逊
 弗雷德里克·杰姆逊
【简介】弗雷德里克·杰姆逊,1934年4月出生于美国的克里夫兰,在耶鲁大学获得硕博士学位,博士专业方向是法国文学,博士论文是《萨特:一种风格的起源》。耶鲁毕业后,在哈佛大学任教。他的文学理论专著《马克思主义与形式》 (1971)、《语言的牢笼》(1972)、《政治无意识》(1981)获得了极高的声誉,被称为“马克思主义的三部曲”。
1985年,杰姆逊访问北京大学,引发了学界关于西方马克思主义以及后现代文化研究的热潮。2002年,他再次登上华东师范大学的演讲台,引起学界广泛关注。
不久前,78岁高龄的杰姆逊开启了他的又一次中国巡讲,先后在北京大学、华东师范大学以及《文汇报》进行了演讲和座谈,本文是其在华东师范大学的演讲——“资本论新解”。
这次演讲的特殊之处需作一些说明。演讲分为两个部分,第一部分谈的是《资本论》第一卷,第二部分谈的是全球化条件下的经验与政治,两部分的相通之处在于:都是重新思考马克思主义的当代相关性。
《资本论》:一本关于失业的书
我对马克思如何来呈现事实不感兴趣,对那些据说是他从事实中推演出来的相关规律也不感兴趣。此次全球范围内的经济危机足以证明马克思对于资本描述的正确性。
《资本论》第一卷已为我们描绘了一幅资本主义的完整图画。对我来说,《资本论》第一卷主要的、形式意义上的问题关乎再现/表 征的问题,即如何从个别元素、历史过程和各种角度来构造一种总体性;尤其是如何公正地对待这种总体性;作为一种关系系统,它不仅是非经验性的,而且是完全处于运动之中的,不断扩张,处于总体化运动之中。这对于资本主义的存在来说是本质性的,也是其独特经济本性最为核心的部分。然而,永恒的崩溃过程对于资本主义结构来说也是本质性的:于是,在这儿我们就有了这样一种机器,它不可避免地会崩溃,因此为了维持自己的实存,它必须不断地用扩张自身、扩张自己控制领域的方式来修复自身。
曾有人认为货币可以解决《资本论》第一卷(论商品)的等价问题,这当然是一种错误的解答,因为货币并不是一种解决方式而是一种中介:货币是二元性的,它被用于表达一种关系,可实际上却隐藏了这种关系本身。这种货币的神秘本性解释了为何如此多的乌托邦围绕以下原则组织架构自身:摆脱货币就将摆脱所有问题。如果货币是一种真正的解决,那么诸如商品及劳动的“合理价格”这样的东西就是可能的,因而社会民主自身是可能的:可以用这样的方式来修补资本主义,从而将它改造成一个公正的社会。另一方面,蒲鲁东的伟大口号:“财产即偷窃”——也让人无法满意,因为它假定以无政府主义精神摆脱货币将废除更深层的问题,可是货币仅仅只是这一问题的症候而已。货币、财产、资本主义自身依赖一种深层的结构性矛盾,或者至少它们依赖一种结构性的悖论(劳动价值论告诉了我们这一悖论的答案),因此无法用法令或修补的方式来解决这一问题。
为了解决这一问题,我们必然会转入生产过程——资本与新的资本只能在这里得到生产。有了生产自身,它很快就将我们引向了劳动价值论的秘密之处,引向了解答。这里的问题表现为:突然间引入了时间——虽说依旧是量化的、静态的、非辩证的方式。劳动价值论导向了所有关于利润率、劳动小时数以及那些有趣的变量组合的计算(这满足了马克思自己的兴趣,他对于数学与微积分的兴趣可以排在第二位)。然而突然之间,这些探究撞了墙:工作日的限制、法律对于工作日的限定、工厂法所要求的限制,突然间阻碍了资本必然的扩张。
因此,论述必须进入一个 新的论域,一个新的层面,问题和解答在这里都充满着强度:赞美集体性或协作。马克思兴高采烈地称之为“赐予资本的免费礼物”:协作劳动以辩证的方式成倍地增加了价值和产品。这当然是亚当·斯密的发现,而在这里它成了马克思的形而上学。马克思主义并非赋予生产以价值,而是赋予集体生产以价值。论协作的一章是《资本论》第一卷跳动的心脏。
然而,这一赞美是短命 的。当协作转化为机器时,这一赞美人类的原则成了名副其实的弗兰肯斯坦所创造的怪物。然而,这一全新现象从根本上转化了整个问题。它导向一种更复杂的新的时间理论以及关于资本主义“毁灭”了过去的理论,同时又导向以下问题的新解答:新的立法阻碍了绝对剩余价值,使之停滞。——提高生产力,强化价值生产却不延长价值生产,这一理论名为“相对剩余价值”论。
辩证地看,这一本来可以让马克思总结自己著作的新解答——机器、工业技术,却导致了一个全新的概念两难。这一两难有两种形式:首先,节省劳动的装置突然导致了劳动者(特别是童工)工作时间令人震惊的上升。其次,节省劳动的机器本该压缩劳动者的数量,不过是以让工人失业的形式进行的。在这一事例中,我们的两难局面具有了另一种形式:如果价值源于劳动,假定劳动者越多,那么所生产的价值也就越多,可资本家为什么坚持压缩劳动者的数量?
在这一点上,整个过程的 真理也变得越来越清晰了,马克思将决定性地阐明他所谓“资本主义积累的一般规律”,即他在同一文本脉络中称之为“绝对”规律的东西。以下是我的引用:“社会的财富即执行职能的资本越大,它的增长的规模和能力越大,从而无产阶级的绝对数量和他们的劳动生产力越大,产业后备军也就越大。可供支配的劳动力同资本的膨胀力一样,是由同一些原因发展起来的。因此,产业后备军的相对量和财富的力量一同增长。”当我们记起这一正式的响亮的表达——“产业后备军”——仅仅指失业者的时候,我们就拥有了更具戏剧意味、更容易获得的辩证悖论。它仅仅意味着资本主义的绝对规律是:增加财富和生产力的同时,不断增加失业者的数量。
现在我们可以回过头来评 价整部《资本论》的意义了。这是一本关于失业的书:抵达《资本论》概念顶端的是以下命题,即产业资本主义一方面生产出数量巨大的资本——这种资本在潜在的意义上是无法投资的,另一方面制造出人数不断上升的失业人群。当前第三阶段资本主义或金融资本的危机可以充分证实这一情况。
并没有描绘社会主义的样子
我想补充的是,资本无关乎劳动:它关乎过度劳动,非人的过长的劳动时间以及前者被限定之后童工的大量产生都是例证。资本也与这一著名的“产业后备军”相关,也就是说,与失业者相关。这里并不涉及Harry Braverman论泰勒制、劳动与垄断资本的经典著作所指向的严格意义上的劳动。然而,以下想法是错误的:历史发展已使这一资本主义总体性的19世纪再现变得陈腐过时:正相反,从马克思的著作中凸显出来的资本的时刻,恰恰在未来的运动中得到了仔细的勾勒——这些空间一方面是信用和金融资本,另一方面是帝国主义(马克思自己关于帝国主义的描述只是简单地谈及诸如澳大利亚这样的移民殖民地,虽然你可以从这一论原始积累的尾声中推导出我们所谓的今日帝国主义)。
因此,我必须下这样一个 结论,《资本论》并不是一本政治著作,除了建议工人组织起来之外,它关于资本的说明并没有任何政治后果。除了在第一部分举了一个假想的例子——联合起来的工人社会——之外,它并没有描绘社会主义的样子。然而,让我更为充分地来解释一下:马克思是一个真正的政治人物,大概除了列宁之外,马克思所具有的杰出的政治本能与政治思考无人能及。他是一个非同寻常的机会主义者,这是马基雅维利意义上的良好的机会主义。为了改变和废除资本主义,他可以向任何可能的道路开放:联合、暴动、议会选举中获胜、回到农村公社,甚至是资本在危机中自我毁灭,等等。如今每一种政治性的马克思主义运动——从社会民主派到列宁主义、毛泽东主义和无政府主义——都是马克思整个方案的可行的候选者,而他的议程则是随历史情境和资本主义自身的发展而改变的。然而,在《资本论》里却没有任何政治方案或是政治策略,《资本论》依然是阿尔都塞意义上的科学而非意识形态。
人们常常哀叹马克思主义 似乎只是纯粹的经济理论,没有为合适的马克思主义政治理论留出足够的空间。而我却认为这正是马克思主义的力量,政治理论和政治哲学总是附带性的。政治只应该是永远警惕的机会主义的事务,却不是任何理论或哲学的事务。在我看来,甚至当前以种种方式重新定义大众民主的努力也偏离了资本主义的本性与结构这一核心议题。永远也没有令人满意的政治解答或政治体系,但是可以有更好的经济体系。马克思主义者和左派需要把精力放在后一方面。
后现代:空间正在消除时间
接下来,我想首先转向后现代性中的日常生活领域,也就是转向主体性构造领域以及某一尚属推测中的新的后现代主体领域。毋庸置疑,信息技术的出现——此种发展完全改造了工业生产甚至是劳动自身——必然会带来主体性的改变,主体醒着的时间完全消耗在各种类型的电脑显示器前了。
就主体性和个人经验而 言,我们对时间的经验正被替换为对空间的经验。可事实是,我们在自己的主观意识里、在现象学的经验和生存体验里都感受着时间的存在。因此,我们需要追问,为什么这种时间感却要屈从于空间的统摄?我想,不仅是柏格森,还有托马斯·曼和普鲁斯特,这些现代主义者都迷恋深度时间。这种迷恋实际上根源于现代化进程的不平衡,于是造成了迟缓的乡村时间和令人眼花缭乱的都市及工业化节奏共存的情况。因此我们说,后现代是现代化的完成,是乡村的消失的结果(农民成为计时工人,原始农业变成农业产业)。在更充分的现代化中,工业劳动力和城市资产阶级的区分都被抹去。每个人都是消费者,每个人都成为雇佣者,一切东西都进了购物中心,空间不过是表面的无限延展。现代化不平衡发展在过去是由区域和民族国家体制造成的,现在则是由全球化造成的,文化自身成为不平衡发展的一个空间。这样,和全球化的联系就十分清楚了:如此辽阔的全球规模绝不可能在以帝国主义、大都市和殖民为代表的现代阶段出现,只有当殖民体系解体了,它才有了出现的条件。
但是就今天的现实而言, 我们应该谈论的倒不是民族解放而是商业,不是一般的跨国公司,而是新的巨型国际商业集团出现所依赖的信息技术。在电脑化时代,空间的距离是如何正被翻译为实际存在时间的共时性的,也就是说,空间正在消除时间。投资、期货、廉价兜售国家货币、剥夺和并购,把未来打包作为可以买卖的商品,这些都被最新出现的交流工具加速实现着,柏格森主义所谓具有绵延特征的时间轨迹已荡然无存。时间的停滞严重地改变了或切割了人类的经验。
我将这称之为时间性的终 结,一切终止于身体和此刻。值得寻找的只是一个强化的现在,它的前后时刻都不再存在。我们的历史观也受到影响。从前的社会没有一个像我们现在的社会这样,有着如此少的功能性记忆和可怜的历史感。这一切和今天个人主体的转换干系重大。在后现代性第一次萌动中,结构主义和后结构主义者宣告了“主体的死亡”。他们看到资产阶级的个人主义因无法和庞大的体制力量抗衡而日趋衰落,同时也看到这种个人主义体现的是具有占有欲和侵略性的自我,而把这种自我唤起的资本主义竞争如今也已衰落。身体是资产阶级文化在消耗殆尽之前的最后现实,是转变、变化和变异的最后发生地,是主体的昂扬自信的激情消退后残留的一点点心情。
政治在本质上反映为掠夺土地
回头反思使我们看到,作为第三个资本主义阶段的全球化只是发生在20世纪60年代的激烈的反殖民运动另一个面向。资本主义在前两个阶段首先建立了民族工业和市场,随后进入帝国主义和抢占殖民地时期,并迅速发展了世界经济的殖民体系。这两个时期的一个共同标志是对他者的建构。首先是各式各样的民族国家把人民分成相互竞争的群体,人们的民族认同只能建立在对外国人和民族敌人的憎恨上,而各自的身份认同则通过相互指认为他者来完成。但是不久,特别是在欧洲,民族主义迅速放弃狭隘的民族立场,允许少数族裔和操不同语言的人发展自己的民族方案。
这种渐进的扩展不可与后 来的全球化相混淆。帝国主义体系是把殖民地的臣民当作他者来殖民的。种族的他者意识和充满欧洲中心主义或美国中心主义式的对落后的、贫弱的臣属文化的轻蔑将殖民地的人民视为前现代的人,将统治性文化和被统治文化区分开来。他者的世界体系就在作为第二个资本主义时期即帝国主义和现代性阶段建立起来了。
显然在反殖民运动中,这 一切都逐渐烟消云散了。臣属的他者们一向无权为自己辩护更不用说来管理自己了,现在则第一次如萨特所说,用自己的声音宣告自己存在的自由。一刹那,资产阶级主体和这些从前的他者们泯然一体了,整个世界被一种新的无名所统治。现在世界上存在的不仅仅是成千上万某个国家的公民,某个民族的语言,而是几十亿人。
那么这一切与政治是什么 关系呢?既然我们一直在讨论空间,我不妨就简单提出一个看法:今日之世界政治皆与房地产相关。后现代政治在本质上反映的是土地掠夺,在地区和全球范围都是如此。无论我们想到的是巴勒斯坦聚居地和难民营问题,还是原材料及其开发政策,或者生态问题,联邦制问题、公民权和移民问题,在大都市同时也在法国简易居住大棚、巴西贫民窟和小镇上发生的中产阶级化问题,今天的一切都和土地相关。按马克思主义术语说,这一切变化归于土地的商品化和残余的封建制以及农民阶层的消失,取而代之的是工业农业、农业商业以及农场工人。
那么时间去哪了?它在我们瞬间拥挤的手机电话和短信发射中,在西雅图、胜利广场和威斯康辛的群众游行人群里。这样的时间,正如我的朋友迈克·哈特和托尼·奈格里所说的,标志着乌合之众的出现。这已不是延绵时间里的政治,而就是此刻和现在的政治。奈格里让我们看到这种时间乃是一种构成性力量而不是被构成的力量。总而言之,这种新的此刻已成为后现代性的标识,一切都停留在此刻和身体里。在这新的无处不在的空间和短暂此刻的辩证法里,历史、历史性和对历史的感觉都成为失败者。过去已经不在,未来却无法憧憬。很显然,历史的消亡为我们的政治和政治实践罩上了阴沉的暗影。
PS: 留下邮箱的读者,可以收到[资本论].卡尔·马克思.全彩版书籍
弗雷德里克·杰姆逊
【简介】弗雷德里克·杰姆逊,1934年4月出生于美国的克里夫兰,在耶鲁大学获得硕博士学位,博士专业方向是法国文学,博士论文是《萨特:一种风格的起源》。耶鲁毕业后,在哈佛大学任教。他的文学理论专著《马克思主义与形式》 (1971)、《语言的牢笼》(1972)、《政治无意识》(1981)获得了极高的声誉,被称为“马克思主义的三部曲”。
1985年,杰姆逊访问北京大学,引发了学界关于西方马克思主义以及后现代文化研究的热潮。2002年,他再次登上华东师范大学的演讲台,引起学界广泛关注。
不久前,78岁高龄的杰姆逊开启了他的又一次中国巡讲,先后在北京大学、华东师范大学以及《文汇报》进行了演讲和座谈,本文是其在华东师范大学的演讲——“资本论新解”。
这次演讲的特殊之处需作一些说明。演讲分为两个部分,第一部分谈的是《资本论》第一卷,第二部分谈的是全球化条件下的经验与政治,两部分的相通之处在于:都是重新思考马克思主义的当代相关性。
《资本论》:一本关于失业的书
我对马克思如何来呈现事实不感兴趣,对那些据说是他从事实中推演出来的相关规律也不感兴趣。此次全球范围内的经济危机足以证明马克思对于资本描述的正确性。
《资本论》第一卷已为我们描绘了一幅资本主义的完整图画。对我来说,《资本论》第一卷主要的、形式意义上的问题关乎再现/表 征的问题,即如何从个别元素、历史过程和各种角度来构造一种总体性;尤其是如何公正地对待这种总体性;作为一种关系系统,它不仅是非经验性的,而且是完全处于运动之中的,不断扩张,处于总体化运动之中。这对于资本主义的存在来说是本质性的,也是其独特经济本性最为核心的部分。然而,永恒的崩溃过程对于资本主义结构来说也是本质性的:于是,在这儿我们就有了这样一种机器,它不可避免地会崩溃,因此为了维持自己的实存,它必须不断地用扩张自身、扩张自己控制领域的方式来修复自身。
曾有人认为货币可以解决《资本论》第一卷(论商品)的等价问题,这当然是一种错误的解答,因为货币并不是一种解决方式而是一种中介:货币是二元性的,它被用于表达一种关系,可实际上却隐藏了这种关系本身。这种货币的神秘本性解释了为何如此多的乌托邦围绕以下原则组织架构自身:摆脱货币就将摆脱所有问题。如果货币是一种真正的解决,那么诸如商品及劳动的“合理价格”这样的东西就是可能的,因而社会民主自身是可能的:可以用这样的方式来修补资本主义,从而将它改造成一个公正的社会。另一方面,蒲鲁东的伟大口号:“财产即偷窃”——也让人无法满意,因为它假定以无政府主义精神摆脱货币将废除更深层的问题,可是货币仅仅只是这一问题的症候而已。货币、财产、资本主义自身依赖一种深层的结构性矛盾,或者至少它们依赖一种结构性的悖论(劳动价值论告诉了我们这一悖论的答案),因此无法用法令或修补的方式来解决这一问题。
为了解决这一问题,我们必然会转入生产过程——资本与新的资本只能在这里得到生产。有了生产自身,它很快就将我们引向了劳动价值论的秘密之处,引向了解答。这里的问题表现为:突然间引入了时间——虽说依旧是量化的、静态的、非辩证的方式。劳动价值论导向了所有关于利润率、劳动小时数以及那些有趣的变量组合的计算(这满足了马克思自己的兴趣,他对于数学与微积分的兴趣可以排在第二位)。然而突然之间,这些探究撞了墙:工作日的限制、法律对于工作日的限定、工厂法所要求的限制,突然间阻碍了资本必然的扩张。
因此,论述必须进入一个 新的论域,一个新的层面,问题和解答在这里都充满着强度:赞美集体性或协作。马克思兴高采烈地称之为“赐予资本的免费礼物”:协作劳动以辩证的方式成倍地增加了价值和产品。这当然是亚当·斯密的发现,而在这里它成了马克思的形而上学。马克思主义并非赋予生产以价值,而是赋予集体生产以价值。论协作的一章是《资本论》第一卷跳动的心脏。
然而,这一赞美是短命 的。当协作转化为机器时,这一赞美人类的原则成了名副其实的弗兰肯斯坦所创造的怪物。然而,这一全新现象从根本上转化了整个问题。它导向一种更复杂的新的时间理论以及关于资本主义“毁灭”了过去的理论,同时又导向以下问题的新解答:新的立法阻碍了绝对剩余价值,使之停滞。——提高生产力,强化价值生产却不延长价值生产,这一理论名为“相对剩余价值”论。
辩证地看,这一本来可以让马克思总结自己著作的新解答——机器、工业技术,却导致了一个全新的概念两难。这一两难有两种形式:首先,节省劳动的装置突然导致了劳动者(特别是童工)工作时间令人震惊的上升。其次,节省劳动的机器本该压缩劳动者的数量,不过是以让工人失业的形式进行的。在这一事例中,我们的两难局面具有了另一种形式:如果价值源于劳动,假定劳动者越多,那么所生产的价值也就越多,可资本家为什么坚持压缩劳动者的数量?
在这一点上,整个过程的 真理也变得越来越清晰了,马克思将决定性地阐明他所谓“资本主义积累的一般规律”,即他在同一文本脉络中称之为“绝对”规律的东西。以下是我的引用:“社会的财富即执行职能的资本越大,它的增长的规模和能力越大,从而无产阶级的绝对数量和他们的劳动生产力越大,产业后备军也就越大。可供支配的劳动力同资本的膨胀力一样,是由同一些原因发展起来的。因此,产业后备军的相对量和财富的力量一同增长。”当我们记起这一正式的响亮的表达——“产业后备军”——仅仅指失业者的时候,我们就拥有了更具戏剧意味、更容易获得的辩证悖论。它仅仅意味着资本主义的绝对规律是:增加财富和生产力的同时,不断增加失业者的数量。
现在我们可以回过头来评 价整部《资本论》的意义了。这是一本关于失业的书:抵达《资本论》概念顶端的是以下命题,即产业资本主义一方面生产出数量巨大的资本——这种资本在潜在的意义上是无法投资的,另一方面制造出人数不断上升的失业人群。当前第三阶段资本主义或金融资本的危机可以充分证实这一情况。
并没有描绘社会主义的样子
我想补充的是,资本无关乎劳动:它关乎过度劳动,非人的过长的劳动时间以及前者被限定之后童工的大量产生都是例证。资本也与这一著名的“产业后备军”相关,也就是说,与失业者相关。这里并不涉及Harry Braverman论泰勒制、劳动与垄断资本的经典著作所指向的严格意义上的劳动。然而,以下想法是错误的:历史发展已使这一资本主义总体性的19世纪再现变得陈腐过时:正相反,从马克思的著作中凸显出来的资本的时刻,恰恰在未来的运动中得到了仔细的勾勒——这些空间一方面是信用和金融资本,另一方面是帝国主义(马克思自己关于帝国主义的描述只是简单地谈及诸如澳大利亚这样的移民殖民地,虽然你可以从这一论原始积累的尾声中推导出我们所谓的今日帝国主义)。
因此,我必须下这样一个 结论,《资本论》并不是一本政治著作,除了建议工人组织起来之外,它关于资本的说明并没有任何政治后果。除了在第一部分举了一个假想的例子——联合起来的工人社会——之外,它并没有描绘社会主义的样子。然而,让我更为充分地来解释一下:马克思是一个真正的政治人物,大概除了列宁之外,马克思所具有的杰出的政治本能与政治思考无人能及。他是一个非同寻常的机会主义者,这是马基雅维利意义上的良好的机会主义。为了改变和废除资本主义,他可以向任何可能的道路开放:联合、暴动、议会选举中获胜、回到农村公社,甚至是资本在危机中自我毁灭,等等。如今每一种政治性的马克思主义运动——从社会民主派到列宁主义、毛泽东主义和无政府主义——都是马克思整个方案的可行的候选者,而他的议程则是随历史情境和资本主义自身的发展而改变的。然而,在《资本论》里却没有任何政治方案或是政治策略,《资本论》依然是阿尔都塞意义上的科学而非意识形态。
人们常常哀叹马克思主义 似乎只是纯粹的经济理论,没有为合适的马克思主义政治理论留出足够的空间。而我却认为这正是马克思主义的力量,政治理论和政治哲学总是附带性的。政治只应该是永远警惕的机会主义的事务,却不是任何理论或哲学的事务。在我看来,甚至当前以种种方式重新定义大众民主的努力也偏离了资本主义的本性与结构这一核心议题。永远也没有令人满意的政治解答或政治体系,但是可以有更好的经济体系。马克思主义者和左派需要把精力放在后一方面。
后现代:空间正在消除时间
接下来,我想首先转向后现代性中的日常生活领域,也就是转向主体性构造领域以及某一尚属推测中的新的后现代主体领域。毋庸置疑,信息技术的出现——此种发展完全改造了工业生产甚至是劳动自身——必然会带来主体性的改变,主体醒着的时间完全消耗在各种类型的电脑显示器前了。
就主体性和个人经验而 言,我们对时间的经验正被替换为对空间的经验。可事实是,我们在自己的主观意识里、在现象学的经验和生存体验里都感受着时间的存在。因此,我们需要追问,为什么这种时间感却要屈从于空间的统摄?我想,不仅是柏格森,还有托马斯·曼和普鲁斯特,这些现代主义者都迷恋深度时间。这种迷恋实际上根源于现代化进程的不平衡,于是造成了迟缓的乡村时间和令人眼花缭乱的都市及工业化节奏共存的情况。因此我们说,后现代是现代化的完成,是乡村的消失的结果(农民成为计时工人,原始农业变成农业产业)。在更充分的现代化中,工业劳动力和城市资产阶级的区分都被抹去。每个人都是消费者,每个人都成为雇佣者,一切东西都进了购物中心,空间不过是表面的无限延展。现代化不平衡发展在过去是由区域和民族国家体制造成的,现在则是由全球化造成的,文化自身成为不平衡发展的一个空间。这样,和全球化的联系就十分清楚了:如此辽阔的全球规模绝不可能在以帝国主义、大都市和殖民为代表的现代阶段出现,只有当殖民体系解体了,它才有了出现的条件。
但是就今天的现实而言, 我们应该谈论的倒不是民族解放而是商业,不是一般的跨国公司,而是新的巨型国际商业集团出现所依赖的信息技术。在电脑化时代,空间的距离是如何正被翻译为实际存在时间的共时性的,也就是说,空间正在消除时间。投资、期货、廉价兜售国家货币、剥夺和并购,把未来打包作为可以买卖的商品,这些都被最新出现的交流工具加速实现着,柏格森主义所谓具有绵延特征的时间轨迹已荡然无存。时间的停滞严重地改变了或切割了人类的经验。
我将这称之为时间性的终 结,一切终止于身体和此刻。值得寻找的只是一个强化的现在,它的前后时刻都不再存在。我们的历史观也受到影响。从前的社会没有一个像我们现在的社会这样,有着如此少的功能性记忆和可怜的历史感。这一切和今天个人主体的转换干系重大。在后现代性第一次萌动中,结构主义和后结构主义者宣告了“主体的死亡”。他们看到资产阶级的个人主义因无法和庞大的体制力量抗衡而日趋衰落,同时也看到这种个人主义体现的是具有占有欲和侵略性的自我,而把这种自我唤起的资本主义竞争如今也已衰落。身体是资产阶级文化在消耗殆尽之前的最后现实,是转变、变化和变异的最后发生地,是主体的昂扬自信的激情消退后残留的一点点心情。
政治在本质上反映为掠夺土地
回头反思使我们看到,作为第三个资本主义阶段的全球化只是发生在20世纪60年代的激烈的反殖民运动另一个面向。资本主义在前两个阶段首先建立了民族工业和市场,随后进入帝国主义和抢占殖民地时期,并迅速发展了世界经济的殖民体系。这两个时期的一个共同标志是对他者的建构。首先是各式各样的民族国家把人民分成相互竞争的群体,人们的民族认同只能建立在对外国人和民族敌人的憎恨上,而各自的身份认同则通过相互指认为他者来完成。但是不久,特别是在欧洲,民族主义迅速放弃狭隘的民族立场,允许少数族裔和操不同语言的人发展自己的民族方案。
这种渐进的扩展不可与后 来的全球化相混淆。帝国主义体系是把殖民地的臣民当作他者来殖民的。种族的他者意识和充满欧洲中心主义或美国中心主义式的对落后的、贫弱的臣属文化的轻蔑将殖民地的人民视为前现代的人,将统治性文化和被统治文化区分开来。他者的世界体系就在作为第二个资本主义时期即帝国主义和现代性阶段建立起来了。
显然在反殖民运动中,这 一切都逐渐烟消云散了。臣属的他者们一向无权为自己辩护更不用说来管理自己了,现在则第一次如萨特所说,用自己的声音宣告自己存在的自由。一刹那,资产阶级主体和这些从前的他者们泯然一体了,整个世界被一种新的无名所统治。现在世界上存在的不仅仅是成千上万某个国家的公民,某个民族的语言,而是几十亿人。
那么这一切与政治是什么 关系呢?既然我们一直在讨论空间,我不妨就简单提出一个看法:今日之世界政治皆与房地产相关。后现代政治在本质上反映的是土地掠夺,在地区和全球范围都是如此。无论我们想到的是巴勒斯坦聚居地和难民营问题,还是原材料及其开发政策,或者生态问题,联邦制问题、公民权和移民问题,在大都市同时也在法国简易居住大棚、巴西贫民窟和小镇上发生的中产阶级化问题,今天的一切都和土地相关。按马克思主义术语说,这一切变化归于土地的商品化和残余的封建制以及农民阶层的消失,取而代之的是工业农业、农业商业以及农场工人。
那么时间去哪了?它在我们瞬间拥挤的手机电话和短信发射中,在西雅图、胜利广场和威斯康辛的群众游行人群里。这样的时间,正如我的朋友迈克·哈特和托尼·奈格里所说的,标志着乌合之众的出现。这已不是延绵时间里的政治,而就是此刻和现在的政治。奈格里让我们看到这种时间乃是一种构成性力量而不是被构成的力量。总而言之,这种新的此刻已成为后现代性的标识,一切都停留在此刻和身体里。在这新的无处不在的空间和短暂此刻的辩证法里,历史、历史性和对历史的感觉都成为失败者。过去已经不在,未来却无法憧憬。很显然,历史的消亡为我们的政治和政治实践罩上了阴沉的暗影。
PS: 留下邮箱的读者,可以收到[资本论].卡尔·马克思.全彩版书籍
↧
spring security使用中的坑
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'org.springframework.security.filterChains': Cannot resolve reference to bean 'org.springframework.security.web.DefaultSecurityFilterChain#6' while setting bean property 'sourceList' with key [6]; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'org.springframework.security.web.DefaultSecurityFilterChain#6': Cannot create inner bean '(inner bean)#4ca65751' of type [org.springframework.security.web.servletapi.SecurityContextHolderAwareRequestFilter] while setting constructor argument with key [8]; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name '(inner bean)#4ca65751': Cannot resolve reference to bean 'myAuthenticationEntryPoint' while setting bean property 'authenticationEntryPoint'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'myAuthenticationEntryPoint' defined in file [/Users/yol/Documents/apache-tomcat-8.0.30/webapps/itsm-acl/WEB-INF/classes/spring/applicationContext-security.xml]: Instantiation of bean failed; nested exception is org.springframework.beans.BeanInstantiationException: Failed to instantiate [org.springframework.security.web.authentication.LoginUrlAuthenticationEntryPoint]: No default constructor found; nested exception is java.lang.NoSuchMethodException: org.springframework.security.web.authentication.LoginUrlAuthenticationEntryPoint.<init>()
org.springframework.beans.factory.CannotLoadBeanClassException: Cannot find class [org.mybatis.spring.SqlSessionFactoryBean] for bean with name 'sqlSessionFactory' defined in file [/Users/yol/Documents/apache-tomcat-8.0.30/webapps/itsm-acl/WEB-INF/classes/spring/ApplicationContext.xml]; nested exception is java.lang.ClassNotFoundException: org.mybatis.spring.SqlSessionFactoryBean
org.springframework.beans.factory.BeanDefinitionStoreException: IOException parsing XML document from ServletContext resource [/WEB-INF/spring-servlet.xml]; nested exception is java.io.FileNotFoundException: Could not open ServletContext resource [/WEB-INF/spring-servlet.xml]
org.springframework.beans.factory.xml.XmlBeanDefinitionStoreException: Line 9 in XML document from file [/Users/yol/Documents/apache-tomcat-8.0.30/webapps/itsm-acl/WEB-INF/classes/spring/applicationContext-security.xml] is invalid; nested exception is org.xml.sax.SAXParseException; lineNumber: 9; columnNumber: 58; The prefix "security" for element "security:filter-chain-map" is not bound.
org.springframework.beans.factory.xml.XmlBeanDefinitionStoreException: Line 28 in XML document from file [/Users/yol/Documents/apache-tomcat-8.0.30/webapps/itsm-acl/WEB-INF/classes/spring/applicationContext-security.xml] is invalid; nested exception is org.xml.sax.SAXParseException; lineNumber: 28; columnNumber: 93; cvc-complex-type.2.4.c: The matching wildcard is strict, but no declaration can be found for element 'bean'.
org.springframework.beans.factory.xml.XmlBeanDefinitionStoreException: Line 29 in XML document from file [/Users/yol/Documents/apache-tomcat-8.0.30/webapps/itsm-acl/WEB-INF/classes/spring/applicationContext-security.xml] is invalid; nested exception is org.xml.sax.SAXParseException; lineNumber: 29; columnNumber: 59; cvc-complex-type.2.4.c: The matching wildcard is strict, but no declaration can be found for element 'constructor-arg'.
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'securityContextPersistenceFilter' defined in file [/Users/yol/Documents/apache-tomcat-8.0.30/webapps/itsm-acl/WEB-INF/classes/spring/applicationContext-security.xml]: Cannot resolve reference to bean 'securityContextRepository' while setting constructor argument; nested exception is org.springframework.beans.factory.NoSuchBeanDefinitionException: No bean named 'securityContextRepository' is defined
org.springframework.beans.factory.xml.XmlBeanDefinitionStoreException: Line 91 in XML document from file [/Users/yol/Documents/apache-tomcat-8.0.30/webapps/itsm-acl/WEB-INF/classes/spring/applicationContext-security.xml] is invalid; nested exception is org.xml.sax.SAXParseException; lineNumber: 91; columnNumber: 54; Open quote is expected for attribute "class" associated with an element type "b:bean".
↧
跨域问题的解决办法Request header field Content-Type is not allowed by Access-Control-Allow-Headers in preflight response.
之前写过一篇,在tomcat里面解决跨域的办法,http://www.paymoon.com:8001/index.php/2016/05/30/java-web-support-cors-visit/
最近在做spring security 的权限问题,做好打了个jar包,供各服务使用,在调用相关login方法的时候,没有通过springMVC的返回,而是自己写了response,这就导致无法通过tomcat的方式解决,必须手动解决。
说到手动解决,先说结果:
[crayon-583580f1a3e58641090681/]
即在response头里面加上各种头信息即可。那么这些头信息是什么意思呢?
即相关原理如下:
本文:http://www.paymoon.com:8001/index.php/2016/11/23/request-header-field-content-type-is-not-allowed-by-access-control-allow-headers-in-preflight-response/
设置浏览器允许访问的服务器的头信息的白名单:
[crayon-583580f1a3e73344613385/]
这样,
HTTP响应头
这部分里列出了跨域资源共享(Cross-Origin Resource Sharing)时,服务器端需要返回的响应头信息.上一部分内容是这部分内容在实际运用中的一个概述.Access-Control-Allow-Origin
返回的资源需要有一个Access-Control-Allow-Origin 头信息,语法如下:
[crayon-583580f1a3e67652606354/]
origin参数指定一个允许向该服务器提交请求的URI.对于一个不带有credentials的请求,可以指定为'*',表示允许来自所有域的请求.
举个栗子,允许来自 http://mozilla.com 的请求,你可以这样指定:
[crayon-583580f1a3e6d928912362/]
如果服务器端指定了域名,而不是'*',那么响应头的Vary值里必须包含Origin.它告诉客户端: 响应是根据请求头里的Origin的值来返回不同的内容的.
Access-Control-Expose-Headers
Requires Gecko 2.0(Firefox 4 / Thunderbird 3.3 / SeaMonkey 2.1)X-My-Custom-Header 和 X-Another-Custom-Header这两个头信息,都可以被浏览器得到.
Access-Control-Max-Age
这个头告诉我们这次预请求的结果的有效期是多久,如下: [crayon-583580f1a3e78715026637/]delta-seconds 参数表示,允许这个预请求的参数缓存的秒数,在此期间,不用发出另一条预检请求.
Access-Control-Allow-Credentials
告知客户端,当请求的credientials属性是true的时候,响应是否可以被得到.当它作为预请求的响应的一部分时,它用来告知实际的请求是否使用了credentials.注意,简单的GET请求不会预检,所以如果一个请求是为了得到一个带有credentials的资源,而响应里又没有Access-Control-Allow-Credentials头信息,那么说明这个响应被忽略了. [crayon-583580f1a3e7d747521262/] 带有credential的请求.Access-Control-Allow-Methods
指明资源可以被请求的方式有哪些(一个或者多个). 这个响应头信息在客户端发出预检请求的时候会被返回. 上面有相关的例子. [crayon-583580f1a3e82971546128/] 发出预检请求的例子见上,这个例子里就有向客户端发送Access-Control-Allow-Methods响应头信息.Access-Control-Allow-Headers
也是在响应预检请求的时候使用.用来指明在实际的请求中,可以使用哪些自定义HTTP请求头.比如 [crayon-583580f1a3e88420577400/] 这样在实际的请求里,请求头信息里就可以有这么一条: [crayon-583580f1a3e8d978073563/] 可以有多个自定义HTTP请求头,用逗号分隔. [crayon-583580f1a3e91756525726/]HTTP 请求头
这部分内容列出来当浏览器发出跨域请求时可能用到的HTTP请求头.注意这些请求头信息都是在请求服务器的时候已经为你设置好的,当开发者使用跨域的XMLHttpRequest的时候,不需要手动的设置这些头信息.Origin
表明发送请求或者预请求的域 [crayon-583580f1a3e97162202231/] 参数origin是一个URI,告诉服务器端,请求来自哪里.它不包含任何路径信息,只是服务器名.Note: Origin的值可以是一个空字符串,这是很有用的.
注意,不仅仅是跨域请求,普通请求也会带有ORIGIN头信息.
Access-Control-Request-Method
在发出预检请求时带有这个头信息,告诉服务器在实际请求时会使用的请求方式 [crayon-583580f1a3e9c428126084/]Access-Control-Request-Headers
在发出预检请求时带有这个头信息,告诉服务器在实际请求时会携带的自定义头信息.如有多个,可以用逗号分开. [crayon-583580f1a3ea1588455460/] 本文:http://www.paymoon.com:8001/index.php/2016/11/23/request-header-field-content-type-is-not-allowed-by-access-control-allow-headers-in-preflight-response/浏览器支持
| Feature | Chrome | Firefox (Gecko) | Internet Explorer | Opera | Safari |
|---|---|---|---|---|---|
| Basic support | 4 | 3.5 | 8 (via XDomainRequest) 10 | 12 | 4 |
注意:
Internet Explorer 8 和 9 通过 XDomainRequest 对象来实现CORS ,但是在IE 10中有完整的实现。Firefox 3.5 就引入了对跨站 XMLHttpRequests 和 Web 字体的支持 ,尽管存在着一些直到后续版本才取消的限制。特别的, Firefox 7 引入了对跨站 WebGL 纹理的 HTTP 请求的支持,而且 Firefox 9 添加对通过 drawImage 在 canvas 上绘图的支持。 相关参考: http://www.paymoon.com:8001/index.php/2016/05/30/java-web-support-cors-visit/ https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Access_control_CORS#Access-Control-Allow-Origin http://stackoverflow.com/questions/16190699/automatically-add-header-to-every-response 本文:http://www.paymoon.com:8001/index.php/2016/11/23/request-header-field-content-type-is-not-allowed-by-access-control-allow-headers-in-preflight-response/↧
↧
[OS][分步式文件系统]什么是文件系统
文件系统是操作系统用于明确磁盘或分区上的文件的方法和数据结构;即在磁盘上组织文件的方法。也指用于存储文件的磁盘或分区,或文件系统种类。
文件系统是对应硬盘的分区的,而不是整个硬盘,不管是硬盘只有一个分区,还是几个分区,不同的分区可以有着不同的文件系统!
而NTFS,FAT32,FAT16还有更早的FAT等等都是文件系统,它们都有着什么区别呢?
NTFS文件系统相比FAT32和FAT16最大优点在于持文件加密,另外一个优点就是能够很好的支持大硬盘,且硬盘分配单元非常小,从而减少了磁盘碎片的产生。NTFS更适合现今硬件配置(大硬盘)和操作系统(XP,Windows7),另外:NTFS文件系统相比FAT32具有更好的安全性,表现在对不同用户对不同文件/文件夹设置的访问权限上,而且CIH病毒在NTFS文件系统下是没有办法传播的!
在运行Windows XP的计算机上,您可以在三种面向磁盘分区的不同文件系统NTFS、FAT32和FAT中加以选择。其中,推荐使用的NTFS文件系统,与FAT或FAT32相比,它具有更为强大的功能,并且包含Active Directory及其它重要安全特性所需的各项功能。另外只有选择NTFS作为文件系统,才可以使用诸如Active Directory和基于域的安全性之类特性。
卷,就是一种逻辑硬盘。这么说你可能很容易就想到分区,一个分区就可以构成一个逻辑硬盘。但是卷与分区最大的不同就是卷可以跨越物理硬盘。
动态磁盘的5种卷:
1、简单卷:构成单个物理磁盘空间的卷。它可以由磁盘上的单个区域或同一磁盘上连接在一起的多个区域组成,可以在同一磁盘内扩展简单卷。
2、跨区卷:简单卷也可以扩展到其它的物理磁盘,这样由多个物理磁盘的空间组成的卷就称为跨区卷。简单卷和跨区卷都不属于RAID范畴。
3、带区卷:以带区形式在两个或多个物理磁盘上存储数据的卷。带区卷上的数据被交替、平均(以带区形式)地分配给这些磁盘,带区卷是所有 Windows 2000 可用的卷中性能最佳的,但它不提供容错。如果带区卷上的任何一个磁盘数据损坏或磁盘故障,则整个卷上的数据都将丢失。带区卷可以看作硬件RAID中的 RAID0。
4、镜像卷:在两个物理磁盘上复制数据的容错卷。它通过使用卷的副本(镜像)复制该卷中的信息来提供数据冗余,镜像总位于另一个磁盘上。如果其中一个物理 磁盘出现故障,则该故障磁盘上的数据将不可用,但是系统可以使用未受影响的磁盘继续操作。镜像卷可以看作硬件RAID中的 RAID1。
5、RAID-5卷:具有数据和奇偶校验的容错卷,有时分布于三个或更多的物理磁盘,奇偶校验用于在阵列失效后重建数据。如果物理磁盘的某一部分失败,您 可以用余下的数据和奇偶校验信息重新创建磁盘上失败的那一部分上的数据。类似硬件RAID中的RAID5,在硬件IDE RAID中,RAID5是很少见的,通常在SCSI RAID卡和高档IDE RAID卡中才能提供,普通IDE RAID卡仅提供RAID0、RAID1和RAID0+1。
| 表四 NTFS和FAT文件系统的比较 | |||
| 比较项 | NTFS | FAT16 | FAT32 |
| 操作系统兼容性 | 一 台运行Windows 2000或Windows XP Professional的机器可以访问NTFS分区上的文件。一台运行Windows NT 4.0(SP4或更高版本) 的机器可以访问该分区上的文件,但一些NTFS功能,例如磁盘配额就不可用了。其他操作系统不能访问。 | MSDOS、Windows的所有版本、Windows NT、Windows XP Professional、OS/2都可以访问。 | 只有在Windows 95 OSR2、Windows 98、Windows Me、Windows 2000以及Windows XP Professional下可以访问。 |
| 卷大小 | 推荐最小卷容量大约是10MB。 推荐实际最大卷容量是2TB。 您也可以使用更大的容量。 不能在软盘上使用。 | 卷最大为4GB。不能在软盘上使用。 | 卷大小从512MB到2TB。 在Windows XP Professional下,一个FAT32卷最大只能被格式化到32GB。 不能在软盘上使用。 |
| 文件大小 | 最大文件尺寸是16TB减去64KB(244减去64KB)。 | 最大文件尺寸为4GB。 | 最大文件尺寸为4GB。 |
| 每卷文件数 | 4,294,967,295 (232减1个文件)。 | 65,536 (216 个文件)。 | 大约4,194,304 (222个文件)。 |
↧
[分布式计算]开发与实现(一)
介绍
分布式计算简单来说,是把一个大计算任务拆分成多个小计算任务分布到若干台机器上去计算,然后再进行结果汇总。 目的在于分析计算海量的数据,从雷达监测的海量历史信号中分析异常信号(外星文明),淘宝双十一实时计算各地区的消费习惯等。 海量计算最开始的方案是提高单机计算性能,如大型机,后来由于数据的爆发式增长、单机性能却跟不上,才有分布式计算这种妥协方案。 因为计算一旦拆分,问题会变得非常复杂,像一致性、数据完整、通信、容灾、任务调度等问题也都来了。 举个例子,产品要求从数据库中100G的用户购买数据,分析出各地域的消费习惯金额等。 如果没什么时间要求,程序员小明就写个对应的业务处理服务程序,部署到服务器上,让它慢慢跑就是了,小明预计10个小时能处理完。 后面产品嫌太慢,让小明想办法加快到3个小时。 平常开发中类似的需求也很多,总结出来就是,数据量大、单机计算慢。 如果上Hadoop、storm之类成本较高、而且有点大才小用。 当然让老板买更好的服务器配置也是一种办法。利用分片算法
小明作为一个有追求有理想的程序员,决定用介于单机计算和成熟计算框架的过度解决方案,这样成本和需求都能满足了。 分布式计算的核心在于计算任务拆分,如果数据能以水平拆分的方式,分布到5台机器上,每台机器只计算自身的1/5数据,这样即能在3小时内完成产品需求了。 如上所述,小明需要把这些数据按照一定维度进行划分。 按需求来看以用户ID划分最好,由于用户之间没有状态上的关联,所以也不需要事务性及二次迭代计算。 小明用简单的hash取模对id进行划分。
[crayon-58397c81ba33e003933312/]
这样程序可以分别部署到5台机器上,然后程序按照配置只取对应余数的用户id,计算出结果并入库。 这种方式多机之间毫无关联,不需要进行通信,可以避免很多问题。 机器上的程序本身也不具备分布式的特性,它和单机一样,只计算自身获取到的数据即可,所以如果某台机器上程序崩溃的话,处理方式和单机一样,比如记录下处理进度,下次从当前进度继续进行后续计算。
利用消息队列
使用分片方式相对比较简单,但有如下不足之处。- 它不具有负载均衡的能力,如果某台机器配置稍好点,它可能最先计算完,然后空闲等待着。也有可能是某些用户行为数据比较少,导致计算比较快完成。
- 还有一个弊端就是每台机器上需要手动更改对应的配置, 这样的话多台机器上的程序不是完全一样的,这样可以用远程配置动态修改的办法来解决。
- 推送消息的,简称Master。
- 消息队列,这里以Rabbitmq为例。
- 各个处理程序,简称Worker或Slave都行。
- 计算任务分发。 Master把需要计算的用户数据,不断的推送消息队列。
- 程序一致性。 Worker订阅相同的消息队列即可,无需更改程序代码。
- 任意扩容。 由于程序完全一样,意味着如果想要加快速度,重复部署一份程序到新机器即可。 当然这是理论上的,实际当中会受限于消息队列、数据库存储等。
- 容灾性。 如果5台中某一台程序挂了也不影响,利用Rabbitmq的消息确认机制,机器崩溃时正在计算的那一条数据会在超时,在其他节点上进行消费处理。
Hadoop简介
Hadoop介绍已经相当多了,这里简述下比如:"Hadoop是一套海量数据计算存储的基础平台架构",分析下这句话。- 其中计算指的是MapReduce,这是做分布式计算用的。
- 存储指的是HDFS,基于此上层的有HBase、Hive,用来做数据存储用的。
- 平台,指可以给多个用户使用,比如小明有一计算需求,他只需要按照对应的接口编写业务逻辑即可,然后把程序以包的形式发布到平台上,平台进行分配调度计算等。 而上面小明的分布式计算设计只能给自己使用,如果另外有小华要使用就需要重新写一份,然后单独部署,申请机器等。Hadoop最大的优势之一就在于提供了一套这样的完整解决方案。
- 图中“大数据计算任务” 对应小明的100G用户数据的计算任务。
- ”任务划分“ 对应Master和消息队列。
- “子任务” 对应Worker的业务逻辑。
- ”结果合并“ 对应把每个worker的计算结果入库。
- “计算结果” 对应入库的用户消费习惯数据。
 PS:为了方便描述,把小明设计的分布式计算,叫做小和尚。
PS:为了方便描述,把小明设计的分布式计算,叫做小和尚。
MapReduce
由于MapReduce计算输入和输出都是基于HDFS文件,所以大多数公司的做法是把mysql或sqlserver的数据导入到HDFS,计算完后再导出到常规的数据库中,这是MapReduce不够灵活的地方之一。 MapReduce优势在于提供了比较简单的分布式计算编程模型,使开发此类程序变得非常简单,像之前的MPI编程就相当复杂。 狭隘的来讲,MapReduce是把计算任务给规范化了,它可以等同于小和尚中Worker的业务逻辑部分。 MapReduce把业务逻辑给拆分成2个大部分,Map和Reduce,可以先在Map部分把任务计算一半后,扔给Reduce部分继续后面的计算。 当然在Map部分把计算任务全做完也是可以的。 关于Mapreduce实现细节部分不多解释,有兴趣的同学可以查相关资料或看下楼主之前的C#模拟实现的博客【探索C#之微型MapReduce】。 如果把小明产品经理的需求放到Hadoop来做,其处理流程大致如下:- 把100G数据导入到HDFS
- 按照Mapreduce的接口编写处理逻辑,分Map、Reduce两部分。
- 把程序包提交到Mapreduce平台上,存储在HDFS里。
- 平台中有个叫Jobtracker进程的角色进行分发任务。 这个类似小和尚的Master负载调度管理。
- 如果有5台机器进行计算的话,就会提前运行5个叫TaskTracker的slave进程。 这类似小和尚worker的分离版,平台把程序和业务逻辑进行分离了, 简单来说就是在机器上运行个独立进程,它能动态加载、执行jar或dll的业务逻辑代码。
- Jobtracker把任务分发到TaskTracker后,TaskTracker把开始动态加载jar包,创建个独立进程执行Map部分,然后把结果写入到HDFS上。
- 如果有Reduce部分,TaskTracker会创建个独立进程把Map输出的HDFS文件,通过RPC方式远程拉取到本地,拉取成功后,Reduce开始计算后续任务。
- Reduce再把结果写入到HDFS中
- 从HDFS中把结果导出。
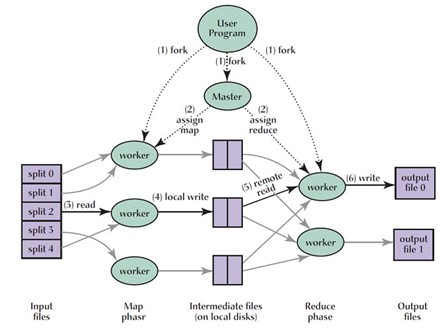
离线计算
通常称Mapreduce及小和尚这种计算为离线计算,因为它对已经持久化的文件数据进行计算,不能实时响应。 还有个原因就是它的处理速度比较慢,它的输入和输出源都是基于HDFS设计,如果数据不是一开始就写入到HDFS上,就会涉及到数据导入导出,这部分相对耗费时间。 而且它的数据流动是基于文件系统的,Map部分输出的数据不是直接传送到Reduce部分,而是先写入HDFS再进行传送。 处理速度慢也是Mapreduce的不足之处,促使了后面实时计算的诞生。 另外个缺点是Mapreduce的计算任务流比较单一,它只有Map、Reduce两部分。 简单的可以只写一部分逻辑来解决,如果想拆分成多个部分,如逻辑A、逻辑B、逻辑C等, 而且一部分计算逻辑依赖上一次计算结果的话,MapReduce处理起来就比较困难了。 像storm框架解决此类问题的方案,也称为流式计算,下一章继续补充。
↧
[分布式计算]开发与实现(二)
实时计算
接上篇,离线计算是对已经入库的数据进行计算,在查询时对批量数据进行检索、磁盘读取展示。 而实时计算是在数据产生时就对其进行计算,然后实时展示结果,一般是秒级。 举个例子来说,如果有个大型网站,要实时统计用户的搜索内容,这样就能计算出热点新闻及突发事件了。 按照以前离线计算的做法是不能满足的,需要使用到实时计算。 小明作为有理想、有追求的程序员开始设计其解决方案了,主要分三部分。- 每当搜索内容的数据产生时,先把数据收集到消息队列,由于其数据量较大,以使用kafka为例。 这个收集过程是一直持续的,数据不断产生然后不断流入到kafka中。
- 要有一个能持续计算的框架,一旦收集到数据,计算系统能实时收到数据,根据业务逻辑开始计算,然后不断产生需要的结果,这里以storm为例。
- 根据结果进行实时展示并入库, 可以一边展示一边入库,对外提供实时查询的服务。这里的入库可以是基于内存的Redis、MongoDB,也可是基于磁盘的HBase、Mysql、SqlServer等。

storm简介
通常都介绍Storm是一个分布式的、高容错的实时计算系统。 “分布式”是把数据分布到多台上进行计算,“高容错”下面谈,这里主要细节介绍下“实时计算”的实现。 storm有个角色叫topology,它类似mapreduce的job,是一个完整的业务计算任务抽象。 上章谈到hadoop的缺点在于数据源单一依赖HDFS,storm中Spout角色的出现解决了这个问题。 在Spout内部我们可以读取任意数据源的数据,比如Redis、消息队列、数据库等等。 而且spout可以是多个,这样更好的分类,比如可以SpoutA读取kafka,SpoutB读取Redis。 示例如下:
流式计算
主流的流式计算有S4、StreamBase、Borealis,其storm也具有流式计算的特性。 流式计算是指“数据能像液体水一样不断的在各个节点间流动,每个节点都可以对“数据(液体水)”进行计算,然后产生新的数据,继续像水一样流动”。如图: 图中Spout就是水龙头,它不断的通过NextData产生数据,然后流动各个Bolt中。 Bolt是各个计算节点上的计算逻辑,它拿到数据后开始计算,完成后流向另外一个,直到完成。 其Bolt也可以是任意个,这比Mapreduce只能分成Map、Reduce两部分好多了。 这样可以在BlotA中计算中间值,然后通过这个中间值去任意数据源拉取数据后,在流动到下一步处理逻辑中, 这个中间值直接在内存中,通过网络流动BlotB上。 其大大增加了其适用范围和灵活度,Spout和bolt的数据流动构成了一个有向无环图。 Bolt示例代码如下。
图中Spout就是水龙头,它不断的通过NextData产生数据,然后流动各个Bolt中。 Bolt是各个计算节点上的计算逻辑,它拿到数据后开始计算,完成后流向另外一个,直到完成。 其Bolt也可以是任意个,这比Mapreduce只能分成Map、Reduce两部分好多了。 这样可以在BlotA中计算中间值,然后通过这个中间值去任意数据源拉取数据后,在流动到下一步处理逻辑中, 这个中间值直接在内存中,通过网络流动BlotB上。 其大大增加了其适用范围和灵活度,Spout和bolt的数据流动构成了一个有向无环图。 Bolt示例代码如下。

归纳总结
结合上篇,发现Hadoop离线计算的计算要求是把业务逻辑包上传到平台上,数据导入到HDFS上,这样才能进行计算。 其产生的结果数据是展示之前就计算好的,另外它的计算是按批次来的,比如很多公司的报表,都是每天凌晨开始计算前一天的数据,以便于展示。 其数据是不动的,计算逻辑也是不动的。 Storm的流式计算同样是把计算逻辑包上传到平台上,由平台调度,计算逻辑是不动的。 但数据可以是任意来源的,不断在计算节点进行流动。 也即是说在数据产生的时刻,就开始进行流动计算,它展示的结果数据是实时变化的。 其数据是流动的,计算逻辑是不动的。storm把产生的每条数据当成一个消息来处理,其内部也是通过消息队列组件zeromq来完成的。高容错性
storm提供了各级别的可靠性保证,一消息从Spout流动到boltA,在流动boltB, 那storm会通过唯一值不断异或的设计去监测这个消息的完成情况,这个监测是一个和业务逻辑类似的bolt,不过它是有storm自身实现的,叫Acker,它的任务就是接收各个消息任务的完成状态,然后告诉Spout这个消息是否已经完全处理。下面是几种异常处理情况:- BoltB所在的节点挂了或消息异常,那么这条消息就没有处理完,Spout可在超时后重新发射该数据即可。
- Acker所在节点挂了后,即当前节点监控的消息完全情况,会全部丢失,Spout会在消息超时做后续处理。
- 如果Spout所在节点挂了,那Spout发射的数据也会全部丢失, 这时可在消息队列中设置超时时间,如果没有一直没对消息进行Ack的话,那么这条消息会重新让其他的Spout重新接收到。这部分需要单独在消息队列中配置,另外storm消息的Ack确认对性能有一定影响,可根据消息的重要性是否要开启它。
- 如果storm平台级别的组件挂了,平台会尝试重启失败的组件,storm除nimbus组件外都是多节点点部署,挂了某一节点,不会对任务计算有所影响。
↧
[ssh what ] SSH4是什么
SS4是什么
SS4是为基于J2EE企业应用提供了全面安全服务
1,将系统的安全逻辑从业务中分离出来
2,提供很多认证授权策略
3,基于URL的WEB资源访问控制
4,业务方法调用访问控制
5,领域对象访问控制 Access Control List(ACL)
6,单点登录(Central Authentication Service) 缓存、信道安全(Channel Security)管理等功能
这里简单翻译了下官方对SS4的定位和说明:
Spring Security为J2EE企业级应用提供了全面的安全服务。
应用级别的安全主要分为“验证( authentication) ”和“(授权) authorization ”两个部分。这也是Spring Security主要需要处理的两个部分。“ Authentication ”指的是建立规则( principal )的过程。规则可以是一个用户、设备、或者其他可以在我们的应用中执行某种操作的其他系统。" Authorization "指的是判断某个 principal 在我们的应用是否允许执行某个操作。在 进行授权判断之前,要求其所要使用到的规则必须在验证过程中已经建立好了。这些概念是通用的,并不是只针对"Spring Security"。
在验证(Authentication )层面, Spring Security 提供了不同的验证模型。大部分的authentication模型来自于第三方或者权威机构或者由一些相关的标准制定组织(如IETF)开发。此外,Spring Security也提供了一些验证特性。特别的,Spring Security目前支持对多种验证方式的整合:
除了验证机制, Spring Security 也提供了一系列的授权能力。主要感兴趣的是以下三个方面:
1、对web请求进行授权
2、授权某个方法是否可以被调用
3、授权访问单个领域对象实例
Reference:
官方介绍 http://docs.spring.io/spring-security/site/docs/current/reference/htmlsingle/↧
↧
[ss4]why 为什么使用Spring Security 4
同比
必须用吗/有同类吗?
当然不是绝对,不使用框架的话,完全可以自己定义扮演各作用的filter,在filter里面做认证,授权,页面显示用标签之类控制,
我先贴上一段官方的推荐:
人们使用 Spring Security的原因有很多,但是大部分项目是发现 Java EE的Servlet 规范或者EJB规范对企业级应用场景提供的安全特性不够深入。提到这些规范,要认识到的一点是,在war包或者ear包的级别上,这些安全机制是不可以移植的。意思就是,如果我们使用了不同的服务器环境,我们通常需要为新的服务器环境重新配置或者开发系统的安全机制。使用Spring Security可以克服这些问题,并且可以给你带来大量的其他有用的、可以自定义的特性。
官方说了三点,一是深入,二是可移植,还可以自定义。
官方说的我和Shiro比较了下,刚才在介绍权限的实现中,我们有提到,除了SS4,也有其它的实现,如Apache Shiro
两者比较为:SS4除了不能脱离Spring,shiro的功能SS4都有。而且Spring Security对Oauth、OpenID也有支持, Shiro则需要自己手动实现。Spring Security的权限细粒度更高
个人在使用中的体验:在认识Spring Security之前,所有的权限验证逻辑都混杂在业务逻辑中,用户的每个操作以前可能都需要对用户是否有进行该项操作的权限进行判断,来达到认证授权的目的。类似这样的权限验证逻辑代码被分散在系统的许多地方,难以维护
也有缺点:
现在的SpringSecurity filter多,配置项多,有些地方需要查,有一定的学习成本。
总结:选择哪个根据自己的业务来定,单就Spring Security的话,掌握的话用起来挺方便的,尤其想做细粒度的控制的话,Spring Security考虑的比较全面,和Spring结合有优势。
说完了SS4的同比优缺点,再说下单就Spring Security的好处。
单就Spring Security的好处
因为 Spring Security 基于Spring的企业应用系统提供声明式的安全访问控制解决方案的安全框架。
它提供了一组可以在Spring应用上下文中配置的Bean,充分利用了Spring IoC,DI(控制反转Inversion of Control ,DI:Dependency Injection 依赖注入)和AOP(面向切面编程)功能,为应用系统提供声明式的安全访问控制功能,减少了为企业系统安全控制编写大量重复代码的工作
可以总结为:轻量<大小,开销,非侵入>,有背景<Spring容器,易开发,AOP,IoC等特性>
why 4 not 3?
除了3的功能4都有外,还修复了很多关键性的bug,以及增加了相当多的特性如SCRF, 并且有些语法两者不兼容,考虑以后长远的使用,所以以4为中心。
↧
[ss4][权限]用户认证与授权过程
1)、安全包括认证授权两个主要操作。
“认证”是为用户建立一个他所声明的主体。主体一般是指用户,设备或可以在你系统中执行行动的其他系统。
“授权”指的一个用户能否在你的应用中执行某个操作。在到达授权判断之前,身份的主体已经由身份验证过程建立了。
用户认证过程<过程见[权限]权限的原理如刚才的流程图>
1.点击一个链接访问一个网页;
2.浏览器发送一个请求到服务器,服务器判断出你正在访问一个受保护的资源;
3.如果此时你并未通过身份认证,服务器发回一个响应提示你进行认证——这个响应可能是一个HTTP响应代码,抑或重定向到一个指定页面;
4.根据系统使用认证机制的不同,浏览器或者重定向到一个登录页面中,或者由浏览器通过一些其它的方式获取你的身份信息(如通过BASIC认证对话框、一个Cookie)
5.浏览器再次将用户身份信息发送到服务器上(可能是一个用户登录表单的HTTP POST信息、也可能是包含认证信息的HTTP报文头);
6.服务器判断用户认证信息是否有效,如果无效,一般情况下,浏览器会要求你继续尝试,这意味着返回第3步。如果有效,则到达下一步;
7.服务器重新响应第2步所提交的原始请求,并判断该请求所访问的程序资源是否在你的权限范围内,如果你有权访问,请求将得到正确的执行并返回结果。否则,你将收到一个HTTP 403错误,这意味着你被禁止访问。
用户授权过程<见[权限]权限的原理>
↧
[SS4层面]SS4是如何把权限实现的原理
本文http://www.paymoon.com:8001/index.php/2016/12/07/how-ss4-apply-the-permission/
如果转载请联系i@paymoon.com
![]()

结合<[权限]权限的原理><[用户层面]用户认证与授权过程>
认证
用户登陆,会被AuthenticationProcessingFilter拦截,调用AuthenticationManager的实现,而且AuthenticationManager会调用ProviderManager来获取用户验证信息(用户信息获取下面会讲),如果验证通过后会将用户的权限信息封装一个User放到spring的全局缓存SecurityContextHolder中,以备后面访问资源时使用。
而验证通过的过程,
通过从AuthenticationProcessingFilter,我们不难找到过滤器实现具体类<之后会讲SS4加载过程>UsernamePasswordAuthenticationFilter:
GenericFilterBean
AbstractAuthenticationProcessingFilter
下的UsernamePasswordAuthenticationFilter<过滤器实现具体类>
本文http://www.paymoon.com:8001/index.php/2016/12/07/how-ss4-apply-the-permission/ 如果转载请联系i@paymoon.com如图:


SecurityAuthenticationFilter就是自己实现了UsernamePasswordAuthenticationFilter的过滤器,
我们通过UsernamePasswordAuthenticationFilter类和其父类,也会到
private String usernameParameter = "username";
private String passwordParameter = "password";
最终我们通过successfulAuthentication方法,找到了AbstractAuthenticationProcessingFilter
AuthenticationSuccessHandler<认证成功后跳转>
AuthenticationFailureHandler<失败后跳转>
本文http://www.paymoon.com:8001/index.php/2016/12/07/how-ss4-apply-the-permission/ 如果转载请联系i@paymoon.com授权
Spring Security称受保护的应用资源为“安全对象”,这包括URL资源和业务类方法。spring AOP中有前置advice(处理、拦截器、通知)、后置advice 、异常advice和环绕advice 。Acegi使用环绕advice对安全对象进行保护。 Acegi通AbstractSecurityInterceptor为安全对象访问提供一致的工作模型,它按照以下流程进行工作:
1. 从SecurityContext中取出已经认证过的Authentication(包括权限信息);
2. 通过反射机制,根据目标安全对象和“配置属性”得到访问目标安全对象所需的权限;
3. AccessDecisionManager根据Authentication的授权信息和目标安全对象所需权限做出是否有权访问的判断。如果无权访问,Acegi将抛出AccessDeniedException异常,否则到下一步;
4. 访问安全对象并获取结果(返回值或HTTP响应);
5. AbstractSecurityInterceptor可以在结果返回前进行处理:更改结果或抛出异常。
本文http://www.paymoon.com:8001/index.php/2016/12/07/how-ss4-apply-the-permission/ 如果转载请联系i@paymoon.com↧